
SHAP:将shap值从KernelExplainer导出到熊猫数据
SHAP:将shap值从KernelExplainer导出到熊猫数据
提问于 2022-05-31 05:34:02
我正在研究一种二进制分类,并使用kernelExplainer来解释我的模型(logistic回归)的结果。
我的代码如下
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=42)
lr = LogisticRegression() # fit and predict statements not shown
masker = Independent(X_train, max_samples=100)
explainer = KernelExplainer(lr.predict,X_train)
bv = explainer.expected_value
sv = explainer.shap_values(X_train)
sdf_train = pd.DataFrame({
'row_id': X_train.index.values.repeat(X_train.shape[1]),
'feature': X_train.columns.to_list() * X_train.shape[0],
'feature_value': X_train.values.flatten(),
'base_value': bv,
'shap_values': sv.values[:,:,1].flatten() #error here I guess
})但是我首先得到了下面的错误。因此,我将最后一行更新为'shap_values': pd.DataFrame(sv).values[:,1].flatten(),但第二个错误如下所示
numpy.ndarray没有属性值。
ValueError:所有数组必须具有相同的长度
对于数据类型,我的X_train是数据格式,sv是numpy.ndarray
我希望我的输出如下所示(忽略基值的更改)。应该是不变的)。但是输出结构如下所示
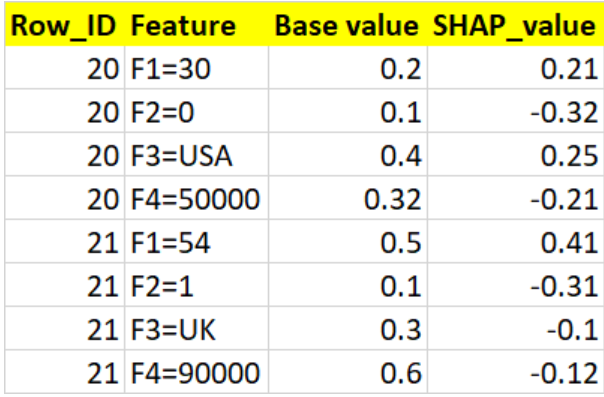
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-31 17:53:22
以下内容如下:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from shap import KernelExplainer
from shap import sample
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=42)
lr = LogisticRegression(max_iter=10000).fit(X_train, y_train)
background = sample(X_train, 100)
explainer = KernelExplainer(lr.predict, background)
sv = explainer.shap_values(X_train)
bv = explainer.expected_value注意sv的形状:
sv.shape(398, 30)这意味着:
sdf_train = pd.DataFrame({
'row_id': X_train.index.values.repeat(X_train.shape[1]),
'feature': X_train.columns.to_list() * X_train.shape[0],
'feature_value': X_train.values.flatten(),
'base_value': bv,
'shap_values': sv.flatten() #error here I guess
})
sdf_train row_id feature feature_value base_value shap_values
0 149 mean radius 13.74000 0.67 0.000000
1 149 mean texture 17.91000 0.67 -0.014988
2 149 mean perimeter 88.12000 0.67 0.060759
3 149 mean area 585.00000 0.67 0.028677页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72442676
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号