
大熊猫的多巢群
大熊猫的多巢群
提问于 2022-05-27 22:09:33
这是我的熊猫资料:
df = pd.DataFrame({'Date': {0: '2016-10-11', 1: '2016-10-11', 2: '2016-10-11', 3: '2016-10-11', 4: '2016-10-11',5: '2016-10-12',6: '2016-10-12',7: '2016-10-12',8: '2016-10-12',9: '2016-10-12'}, 'Stock': {0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E', 5: 'F', 6: 'G', 7: 'H',8: 'I', 9:'J'}, 'Sector': {0: 0,1: 0, 2: 1, 3: 1, 4: 1, 5: 0, 6:0, 7:0, 8:1, 9:1}, 'Segment': {0: 0, 1: 1, 2: 1, 3: 1, 4: 1, 5: 1, 6:2,7:2,8:3,9:3}, 'Range': {0: 5, 1: 0, 2: 1, 3: 0, 4: 2, 5: 6, 6:0, 7:23, 8:5, 9:5}})以下是它的外观:
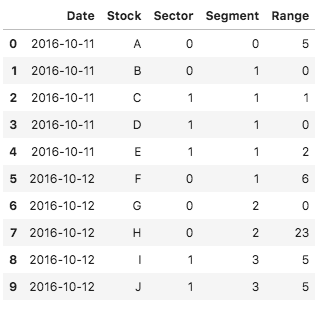
我想添加以下列:
按日期分组的
- 'Date_Range_Avg':‘范围’平均值和按日期和分段
分组的‘范围’的Sector
- 'Date_Segment_Range_Avg':平均值
这将是产出:
res = pd.DataFrame({'Date': {0: '2016-10-11', 1: '2016-10-11', 2: '2016-10-11', 3: '2016-10-11', 4: '2016-10-11',5: '2016-10-12',6: '2016-10-12',7: '2016-10-12',8: '2016-10-12',9: '2016-10-12'}, 'Stock': {0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E', 5: 'F', 6: 'G', 7: 'H',8: 'I', 9:'J'}, 'Sector': {0: 0,1: 0, 2: 1, 3: 1, 4: 1, 5: 0, 6:0, 7:0, 8:1, 9:1}, 'Segment': {0: 0, 1: 1, 2: 1, 3: 1, 4: 1, 5: 1, 6:2,7:2,8:3,9:3}, 'Range': {0: 5, 1: 0, 2: 1, 3: 0, 4: 2, 5: 6, 6:0, 7:23, 8:5, 9:5}, 'Date_Range_Avg':{0: 1.6, 1: 1.6, 2: 1.6, 3: 1.6, 4: 1.6, 5: 7.8, 6: 7.8, 7: 7.8, 8:7.8, 9: 7.8}, 'Date_Sector_Range_Avg':{0: 2.5, 1: 2.5, 2: 1, 3: 1, 4: 1, 5: 9.67, 6: 9.67, 7: 9.67, 8: 9.67, 9: 9.67}, 'Date_Segment_Range_Avg':{0: 5, 1: 0.75, 2: 0.75, 3: 0.75, 4: 0.75, 5: 6, 6: 11.5, 7: 11.5, 8: 5, 9: 5}})这就是它的样子:
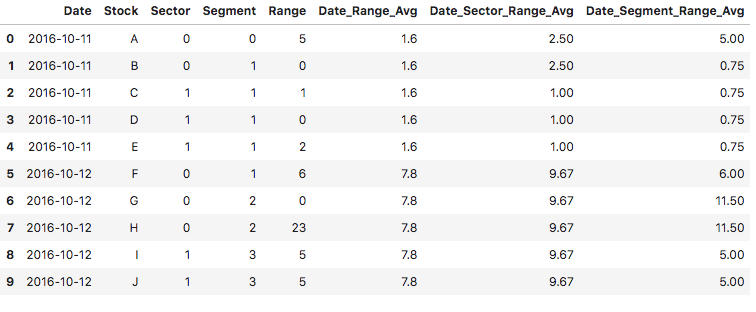
注:我已经舍入了一些值--但这个舍入对于我的问题并不重要(请随意舍入)。
我知道我可以分别进行这些分组,但我认为它效率低下(我的数据集包含数百万行)。
本质上,我想先按Date进行分组,然后再使用它来进行Date and Segment和Date and Sector两种更细粒度的分组。
怎么做?
我最初的预感是这样的:
day_groups = df.groupby("Date")
df['Date_Range_Avg'] = day_groups['Range'].transform('mean')然后再使用day_groups来执行以下两个更细粒度的组:
df['Date_Sector_Range_Avg'] = day_groups.groupby('Segment')[Range].transform('mean')当你得到它的时候,它不起作用:
'AttributeError:'DataFrameGroupBy‘对象没有属性’groupby‘
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-27 22:38:35
当聚合函数被矢量化时,groupby运行得非常快。如果您担心性能问题,请先尝试一下,看看它是否是程序中的真正瓶颈。
您可以创建保存每个groupby的结果的临时数据帧,然后使用df依次对它们进行merge。
group_bys = {
"Date_Range_Avg": ["Date"],
"Date_Sector_Range_Avg": ["Date", "Sector"],
"Date_Segment_Range_Avg": ["Date", "Segment"]
}
tmp = [
df.groupby(columns)["Range"].mean().to_frame(key)
for key, columns in group_bys.items()
]
result = df
for t in tmp:
result = result.merge(t, left_on=t.index.names, right_index=True)结果:
Date Stock Sector Segment Range Date_Range_Avg Date_Sector_Range_Avg Date_Segment_Range_Avg
0 2016-10-11 A 0 0 5 1.6 2.500000 5.00
1 2016-10-11 B 0 1 0 1.6 2.500000 0.75
2 2016-10-11 C 1 1 1 1.6 1.000000 0.75
3 2016-10-11 D 1 1 0 1.6 1.000000 0.75
4 2016-10-11 E 1 1 2 1.6 1.000000 0.75
5 2016-10-12 F 0 1 6 7.8 9.666667 6.00
6 2016-10-12 G 0 2 0 7.8 9.666667 11.50
7 2016-10-12 H 0 2 23 7.8 9.666667 11.50
8 2016-10-12 I 1 3 5 7.8 5.000000 5.00
9 2016-10-12 J 1 3 5 7.8 5.000000 5.00另一种选择是使用transform,并避免多次合并:
# reusing your code
group_bys = {
"Date_Range_Avg": ["Date"],
"Date_Sector_Range_Avg": ["Date", "Sector"],
"Date_Segment_Range_Avg": ["Date", "Segment"]
}
tmp = {key : df.groupby(columns)["Range"].transform('mean')
for key, columns in group_bys.items()
}
df.assign(**tmp)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72411501
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号