
如何重视滑雪隔离林的一些特点
如何重视滑雪隔离林的一些特点
提问于 2022-05-27 07:24:54
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-27 22:39:49
您可以在不更改源代码的情况下实现这一点。相反,您可以通过复制希望增加权重的功能来调整输入数据。如果您有一个功能出现两次,树将使用它两次来分割您的数据,这在实践中将意味着已经翻倍的功能重量。
除此之外,您还可以选择减少隔离林在每个树中使用的功能数量。这是由参数max_features控制的。默认值1.0确保每个树都将使用每个特性。通过减少它,会有更多的树被训练,而不需要在你的输入中使用较少的特征。
插图
负载数据
from sklearn.ensemble import IsolationForest
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
X = data.data
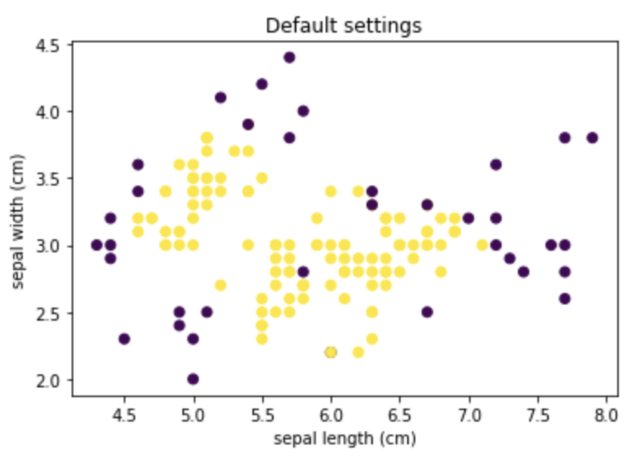
df = pd.DataFrame(X, columns=data.feature_names)默认设置
IF = IsolationForest()
IF.fit(df)
preds = IF.predict(df)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=preds)
plt.title("Default settings")
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.show()
加权设置
df1 = df.copy()
weight_feature = 10
for i in range(weight_feature):
df1["duplicated_" + str(i)] = df1["sepal length (cm)"]
IF1 = IsolationForest(max_features=0.3)
IF1.fit(df1)
preds1 = IF1.predict(df1)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=preds1)
plt.title("Weighted settings")
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.show()
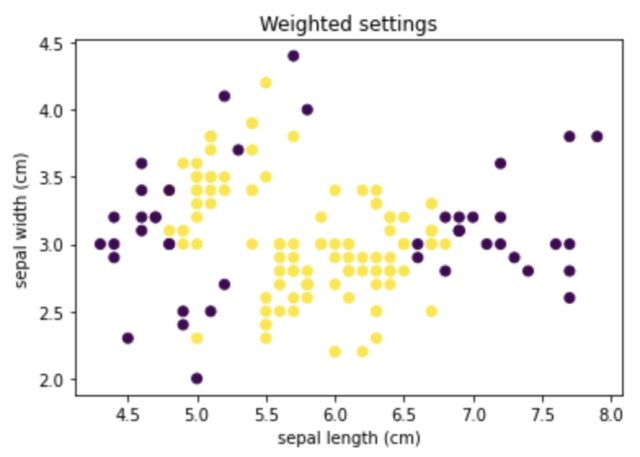
正如你所看到的,第二个选项更密集地使用了X轴来确定哪一个是异常值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72401876
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号