
回填和前向填充NaNs和Zeros
回填和前向填充NaNs和Zeros
提问于 2022-05-27 02:28:56
我正努力把员工的工作经验(年数)倒过来。我想要达到的目标是:
雇员200
2019-3年,2018-2年,2017 -1年
雇员300
像南一样
雇员400
2018-3年,2017年-2年
雇员500
2018-6年,2017年-5年,2016年-4年
我真的很难让它以-1 (+1)的增量来回填(前填充)。如果非NaN/零值位于中间,则更棘手,就像雇员500的情况一样。
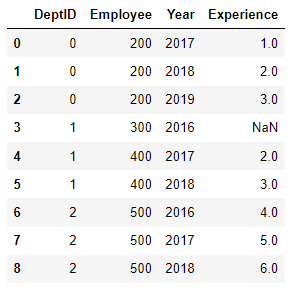
df_test = pd.DataFrame({'DeptID':[0,0,0,1,1,1,2,2,2],
'Employee':[200, 200, 200, 300, 400, 400, 500, 500, 500],
'Year':[2017, 2018, 2019, 2016, 2017, 2018, 2016, 2017, 2018],
'Experience':[np.nan , np.nan, 3, np.nan, 2, np.nan, 0, 5, 0]
})回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-27 03:16:28
假设每个员工都有一次非零和非nan体验,那么试试下面的方法
df_test = pd.DataFrame({'DeptID':[0,0,0,1,1,1,2,2,2],
'Employee':[200, 200, 200, 300, 400, 400, 500, 500, 500],
'Year':[2017, 2018, 2019, 2016, 2017, 2018, 2016, 2017, 2018],
'Experience':[np.nan , np.nan, 3, np.nan, 2, np.nan, 0, 5, 0]
})
# find the last nonzero, non-nan value for each employee
nonzero = df_test[df_test.Experience.ne(0) & df_test.Experience.notna()].drop_duplicates('Employee', keep='last').reset_index().set_index('Employee')
# map the difference between experience and index of the nonzero value of the employees to employee column
# add it to index
df_test['Experience'] = df_test.index + df_test.Employee.map(nonzero.Experience - nonzero['index'])
df_test
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72399848
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号