
跨子集滚动和
我有一个按季度显示感兴趣值( ee )的数据集,以及多个字段,这些字段表示人口中各个子集中ee的数量,具体如下:
test=pd.DataFrame(data={'cyq':['2018Q1']*3+['2018Q2']*3+['2018Q3']*3+['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})我试图得到季度的ee的滚动和,特定于其他字段的每个唯一子集,在这个例子中是物种,和组。在我的实际数据集中,总共有六个标识字段。
以下内容如下:
test.groupby(['cyq','species','group']).ee.rolling(window=2).sum()正在生产所有的NaNs。其他解决方案,我已经找到了滚动之和在每个季度,或只在一个识别字段。我的目标是取一个滚动的总和,将犬类a、犬类b和猫a识别为不同的值,并按季度滚动它们的ee值:
非常感谢你的帮助。我觉得有一个简单的解决方案,但是我在这里发现的这个问题的变化并不适用于我的数据集。
编辑:我拼凑出了以下解决方案,但确定这并不是实现目标的最有效或最高效的方法:
test=pd.DataFrame(data={'cyq':['2018Q1']*3+['2018Q2']*3+['2018Q3']*3+['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})
test['cyq']=test.cyq.apply(lambda x: pd.to_datetime(x))
test=test.groupby(['group','species','cyq']).sum().reset_index(level=2)
test=test.groupby(level=[i for i in range(test.index.nlevels)]).rolling('100D',min_periods=2,on='cyq').sum()
test.droplevel([i for i in range(int(test.index.nlevels/2))]).reset_index()回答 2
Stack Overflow用户
发布于 2022-05-26 20:58:09
EDIT2,关于评论,这里有一个可能的解决方案吗?请在您的真实数据上尝试并验证它。
test['cyq']= pd.to_datetime(test['cyq'])
test=test.set_index('cyq').groupby(['species','group']).rolling('100D',min_periods=2).sum()编辑,根据你在另一个答案上的评论,我想我知道你在搜索什么。错误是你把你不想去的宿舍也包括进去了。
test=pd.DataFrame(data={'cyq':['2018Q1']*3+['2018Q2']*3+['2018Q3']*3+['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})
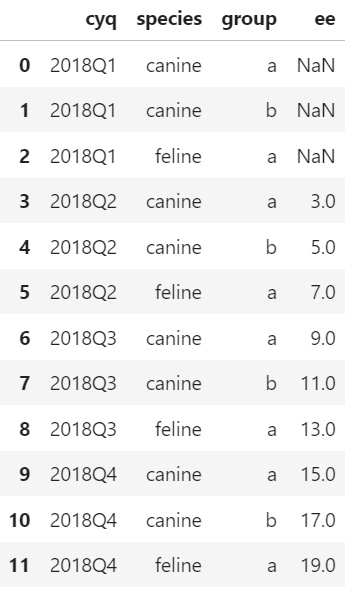
res = test.groupby(['species', 'group'], as_index = False)['ee'].rolling(window=2).sum().join(test['cyq'])
print(res)
species group ee cyq
0 canine a NaN 2018Q1
3 canine a 3.0 2018Q2
6 canine a 9.0 2018Q3
9 canine a 15.0 2018Q4
1 canine b NaN 2018Q1
4 canine b 5.0 2018Q2
7 canine b 11.0 2018Q3
10 canine b 17.0 2018Q4
2 feline a NaN 2018Q1
5 feline a 7.0 2018Q2
8 feline a 13.0 2018Q3
11 feline a 19.0 2018Q4您不会得到任何结果,因为在groupby之后提供的示例中,每个组正好是一行。你的滚动窗口是2。看看文档 for pd.rolling,引用min_periods的话。
min_periods:int,默认无 窗口中有一个值所需的最少观察数;否则,结果是np.nan。对于由整数指定的窗口,min_periods将默认为该窗口的大小。
因为您从来没有两个窗口,所以所有值都返回NaN。如果您的实际数据更大,并且每个组都有更多的值,那么您的代码就可以工作了。您可以将min_periods设置为1,以便在至少有一个值的情况下获得返回值。
Stack Overflow用户
发布于 2022-05-26 20:28:23
我不认为你从你的第一段代码中得到了什么,因为在这个分组的基础上,没有任何东西会回来。但是,通过删除分组,我能够非常接近您正在寻找的内容。
test=pd.DataFrame(data={'cyq':['2018Q1']*3+['2018Q2']*3+['2018Q3']*3+['2018Q4']*3,
'species':['canine','canine','feline']*4,
'group':['a','b','a']*4,
'ee':range(12)})
test['ee'] = test['ee'].rolling(window = 2).sum()
testhttps://stackoverflow.com/questions/72397613
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号