
在Python中可以为null的两行中查找日期之间的差异
在Python中可以为null的两行中查找日期之间的差异
提问于 2022-05-24 23:15:23
我有一个包含两个datetime列的数据集(比方说Call_Date & Transaction_Date)。Call_Date总是被填充,因为我们只是在寻找能够到达消费者的实例。然后,如果使用者进行事务处理,我们将填充Transaction_Date。因此,并不总是填充Transaction_date。
我想要了解的是,当这两个日期都被填充时,在调用完成事务之后的多少天,而不排除使用者没有进行事务处理的情况。
有什么办法吗?
极小例子
df = pd.DataFrame({'Customer': ['ABC','XYZ','PQR'],
'Call_Date': ['12/8/2021 2:31:07 PM','20/8/2021 5:27:02 AM','5/8/2021 7:29:40 PM'],
'Transaction_Date': ['16/8/2021 9:21:58 PM', pd.NaT, pd.NaT]})回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-25 00:20:57
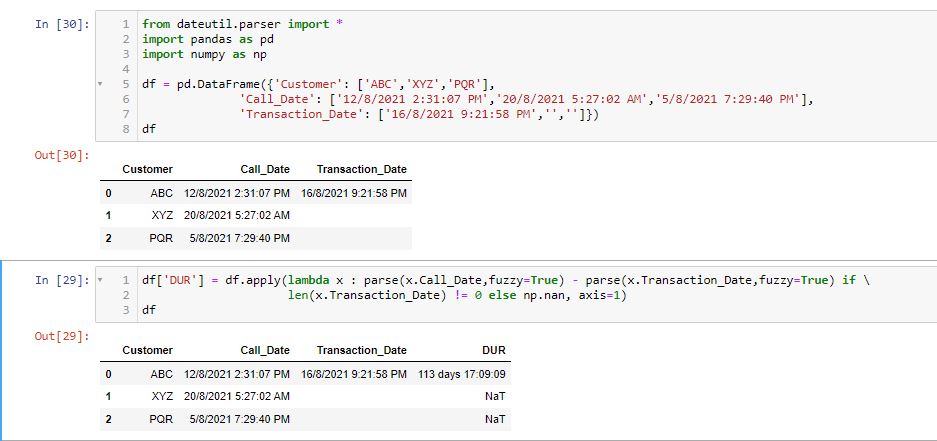
跟着为我工作。请检查附加的图像以查看输出。
from dateutil.parser import *
import pandas as pd
import numpy as np
df = pd.DataFrame({'Customer': ['ABC','XYZ','PQR'],
'Call_Date': ['12/8/2021 2:31:07 PM','20/8/2021 5:27:02 AM','5/8/2021 7:29:40 PM'],
'Transaction_Date': ['16/8/2021 9:21:58 PM','','']})
df['DUR'] = df.apply(lambda x : parse(x.Call_Date,fuzzy=True) - parse(x.Transaction_Date,fuzzy=True) if \
len(x.Transaction_Date) != 0 else np.nan, axis=1)另一种方法可以如下所示,包括一个函数diff()来实现异常处理,所以现在对任何类型的Null/String/datetime都不会有问题。
请查看图书馆文档:https://dateutil.readthedocs.io/en/stable/parser.html
def diff(datetime_old, datetime_new):
try: return abs(parse(str(datetime_new), fuzzy=True) - parse(str(datetime_old), fuzzy=True))
except: return np.nan
df['DUR'] = df.apply(lambda x : diff(x.Call_Date, x.Transaction_Date) if pd.notnull(x.Transaction_Date) else np.nan, axis=1)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72370405
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号