
如何读出JBIG2算法在我的pdf中使用的符号字典的属性?
我有一个PDF,其中包含一个长长的列表编号,它是使用JBIG2算法压缩的。当我查找我可以找到的文件的内部文件结构时,我的页面是用两个不同的XObjects构建的:
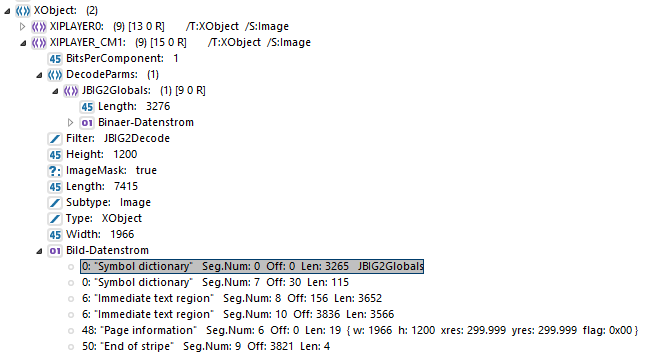
(图为Acrobat飞行前->内部结构。)
我可以很容易地查看第一个名为"XIPLAYER0“(而不是图片)的细节--如果我愿意的话,它甚至可以一点一点地提供给我信息。第二个是我对它感兴趣的那个。在它中,我可以看到图像是用2个“符号词典”(第一个标记为灰色)构建的。能在这本字典里看到不同的词条吗?或者仅仅为其中之一得到一些元数据?
回答 1
Stack Overflow用户
发布于 2022-05-24 15:08:05
这并不是关于PDF的,PDF只是JBIG2格式及其符号字典的容器,这正是您真正感兴趣的。
但是,作为第一步,您需要将JBIG2图像从PDF中提取出来:
这就提到了poppler,poppler确实有一个Python绑定/包装器:
https://pypi.org/project/python-poppler/
一旦您获得了这些JBIG2文件,也许这会有所帮助:
更大的项目有一个命令行util,它有一个“转储”选项,但是消息来源说它没有实现^1。
case dump:
fprintf(stderr, "Sorry, segment dump not yet implemented\n");
break;因此,如果你只是好奇/这是一个学术问题,答案看起来是“不完全”。如果你需要阅读课文,那么OCR怎么样?
https://stackoverflow.com/questions/72361820
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号