
用bs4擦伤圆柱体的记分
用bs4擦伤圆柱体的记分
提问于 2022-05-09 18:18:41
我正在为我的大学项目从红薯上刮一些数据,但我不能刮番茄机的分数。
https://www.rottentomatoes.com/m/doctor_strange_in_the_multiverse_of_madness
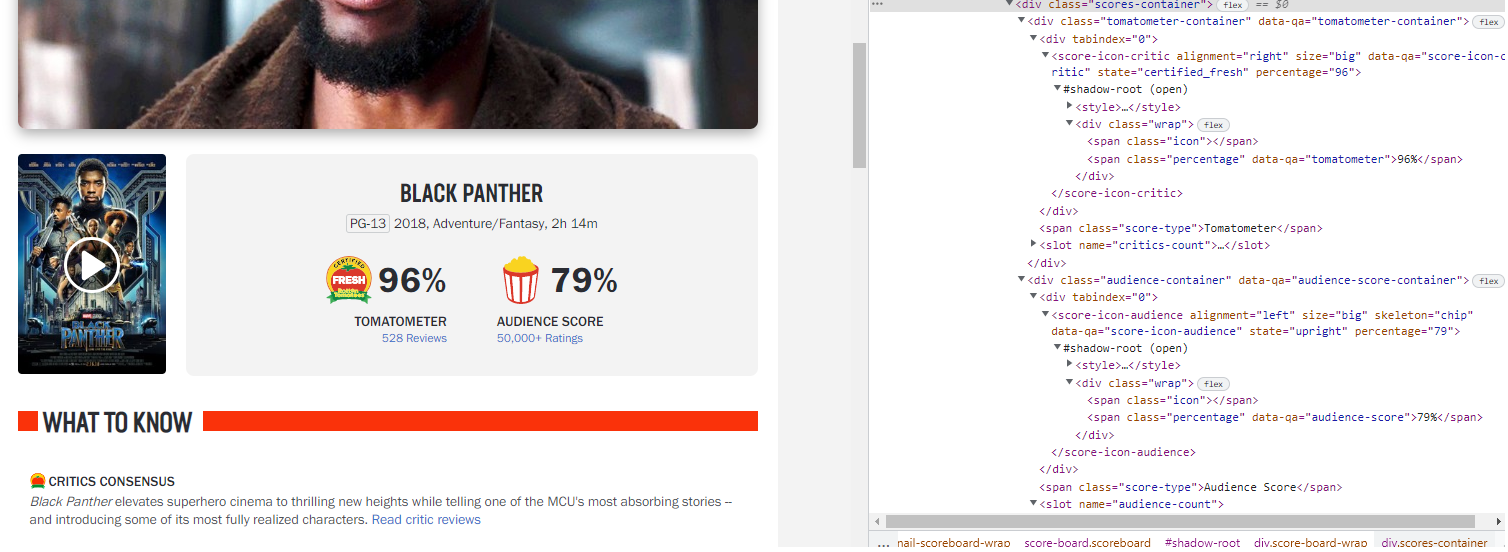
我的代码是
tomato = bs.find('span', {'class':'percentage'}, {'data-qa':'tomatometer'}).text我试过几种方法,但没有一种奏效
回答 1
Stack Overflow用户
发布于 2022-05-09 21:15:02
您看到的数据存储在页面中的<score-board>标记中:
import requests
from bs4 import BeautifulSoup
url = "https://www.rottentomatoes.com/m/doctor_strange_in_the_multiverse_of_madness"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
board = soup.find("score-board")
print(
f'Audience Score: {board["audiencescore"]}% Tomatometer: {board["tomatometerscore"]}%'
)指纹:
Audience Score: 87% Tomatometer: 75%页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72176548
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号