
从SQLLIte数据库中持久化"nana值“
我正在尽我最大的努力从具有nan值的列和行中删除所有值,否则我的代码就会中断这些值。
在你问之前,是的,我问谷歌,我有正确的代码块来删除所有nan值。
# ____________________________________________________________________________________ SQLite3 Integration
# Read sqlite query results into a pandas DataFrame
con = sqlite3.connect("Sensors Database.db") # Name of database
df = pd.read_sql_query("SELECT * FROM Hollow_Data_1", con)
# Verify that result of SQL query is stored in the dataframe
con.close()
# print the database table in Console
# drop all nan value
df = df.dropna(subset=['latitude', 'longitude', 'alt'])
print(df)
# df = pd.read_csv('DutchHollow_07222018_non_nan.csv')最后一行是测试CSV字符串,以确保我的代码在没有这些nan值的情况下工作。
只有在运行打印(df.head())时,我才会看到同样的情况。就像它从来没有掉下来一样。
数据库片段:
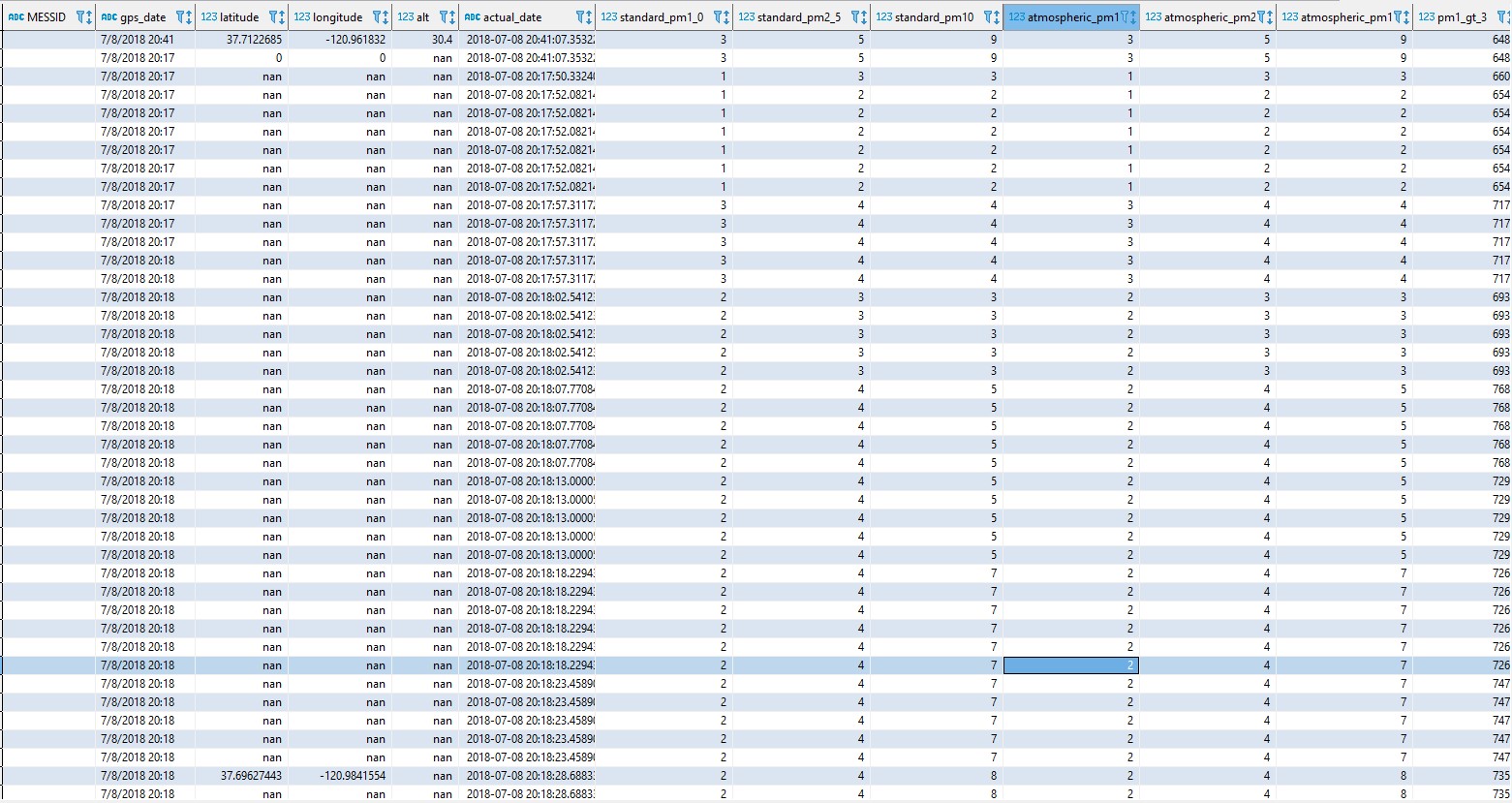
这个数据库被设计用来从无人机的传感器收集数据,而纳米值是糟糕的数据(无人机正在启动和编程飞行,而不是在空中)。我的仪表板将这些点绘制成Mapbox。
这可以通过实时数据库模式中的NULL来处理,因此它在表中没有这些NAN值。
本质上,我希望它删除所有具有NAN值的行和列。
我试着复制数据
nan_df = dropna() and dropna(how=all) dropna(subset=['latitude', 'longitude', 'alt']) or (inplace=True) 每次我print(df.head),它就会持续存在。就好像dropna不在那里一样。
回答 1
Stack Overflow用户
发布于 2022-05-08 04:18:17
乱搞你的数据,似乎你的csv只是有点磨损。
而不是真正的nans,您的nans是以nan <--是的,它前面有一个空格--出现的。
给定您的df:
gps_date latitude longitude alt ... Temperature Humidity Pressure Voc
0 7/8/2018 20:41 37.7122685 -120.961832 30.4 ... 39.55 1011.68 27.130 1277076.0
1 7/8/2018 20:17 0 0 nan ... 39.66 1014.00 28.967 10943.0
2 7/8/2018 20:17 nan nan nan ... 41.19 1014.02 28.633 15895.0
3 7/8/2018 20:17 nan nan nan ... 42.05 1014.04 27.901 21403.0
4 7/8/2018 20:17 nan nan nan ... 42.49 1014.05 27.169 27909.0
... ... ... ... ... ... ... ... ... ...
4060 7/22/2018 21:50 37.7085305 -121.072975 38.1 ... 42.54 1014.45 22.296 995778.0
4061 7/22/2018 21:50 37.70852517 -121.0729798 38.1 ... 42.53 1014.45 22.305 998589.0
4062 7/22/2018 21:50 37.7085225 -121.0729787 38.2 ... 42.54 1014.44 22.307 999294.0
4063 7/22/2018 21:50 37.70852533 -121.072976 38.4 ... 42.54 1014.45 22.323 1000000.0
4064 7/22/2018 21:50 37.70853217 -121.0729735 38.6 ... 42.54 1014.46 22.323 999294.0
[4065 rows x 21 columns]做:
df = df.replace(' nan', np.nan)
df = df.dropna()输出:
gps_date latitude longitude alt ... Temperature Humidity Pressure Voc
0 7/8/2018 20:41 37.7122685 -120.961832 30.4 ... 39.55 1011.68 27.130 1277076.0
101 7/8/2018 20:19 37.72486737 -120.9415272 -179.979 ... 42.33 999.77 22.664 511798.0
103 7/8/2018 20:19 37.7193156 -120.9505354 10.642 ... 42.22 999.79 22.596 521619.0
104 7/8/2018 20:19 37.71908237 -120.9503735 1.043 ... 42.12 999.88 22.523 524717.0
105 7/8/2018 20:19 37.71871426 -120.9502485 -11.66 ... 42.03 999.80 22.539 528246.0
... ... ... ... ... ... ... ... ... ...
4060 7/22/2018 21:50 37.7085305 -121.072975 38.1 ... 42.54 1014.45 22.296 995778.0
4061 7/22/2018 21:50 37.70852517 -121.0729798 38.1 ... 42.53 1014.45 22.305 998589.0
4062 7/22/2018 21:50 37.7085225 -121.0729787 38.2 ... 42.54 1014.44 22.307 999294.0
4063 7/22/2018 21:50 37.70852533 -121.072976 38.4 ... 42.54 1014.45 22.323 1000000.0
4064 7/22/2018 21:50 37.70853217 -121.0729735 38.6 ... 42.54 1014.46 22.323 999294.0
[3939 rows x 21 columns]或者,您可以在每一列上运行类似df.latitude = df.latitude.astype(float)的内容,这似乎会自动修复磨损的nans 和,从而为这些列提供正确的dtype。
https://stackoverflow.com/questions/72154417
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号