
如何在Python中添加2D数组的相邻元素而不必使用嵌套循环?
我希望添加数组的相邻元素"3x3“,并创建新的数组。当使用嵌套循环时,这需要时间,因为这段代码将被调用数千次。
import tensorflow as tf
import numpy as np
rows=6
cols=8
array1 = np.random.randint(10, size=(rows, cols))
print(array1)
array2=np.zeros((rows-2,cols-2))
for i in range(rows-2):
for j in range(cols-2):
array2[i,j]=np.sum(array1[i:i+3,j:j+3])# print()
print("output\n",array2)
##My output
[[9 4 9 6 1 4 9 0]
[2 3 4 2 0 0 9 0]
[2 8 9 7 6 9 4 8]
[6 3 6 7 7 0 7 5]
[2 1 4 1 7 6 9 9]
[1 1 2 6 3 8 1 4]]
output
[[50. 52. 44. 35. 42. 43.]
[43. 49. 48. 38. 42. 42.]
[41. 46. 54. 50. 55. 57.]
[26. 31. 43. 45. 48. 49.]]通过矢量化,这是可以解决的。然而,我尝试了不同的技术,但从来没有任何运气,如整形然后添加数组,只使用一个循环的大小行或科尔。注意:在我的项目中,行和科尔的大小可能非常大。它类似于二维卷积和核卷积。问题是,是否可以在不使用循环的情况下实现这一点?,或者至少降低它的时间复杂度,“只使用行或cols作为循环的大小”。
回答 3
Stack Overflow用户
发布于 2022-05-07 15:44:50
我为这个案子找到了更好的解决方案。使用来自scipy.signal模块的函数scipy.signal,我使用np.ones和np.array函数将输入声明为numpy数组,并使用convolve2d将内核应用于每个映像的每个部分。这被称为卷积滤波器和核,在python的图像处理中经常使用它。
In [50]: import numpy as np
In [55]: np.ones((3,3))
Out[55]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
In [59]: input_matrix
Out[59]:
array([[9, 4, 9, 6, 1, 4, 9, 0],
[2, 3, 4, 2, 0, 0, 9, 0],
[2, 8, 9, 7, 6, 9, 4, 8],
[6, 3, 6, 7, 7, 0, 7, 5],
[2, 1, 4, 1, 7, 6, 9, 9],
[1, 1, 2, 6, 3, 8, 1, 4]])
In [60]: kernel
Out[60]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
In [61]: from scipy.signal import convolve2d
In [63]: convolve2d(input_matrix, kernel, 'valid')
Out[63]:
array([[50., 52., 44., 35., 42., 43.],
[43., 49., 48., 38., 42., 42.],
[41., 46., 54., 50., 55., 57.],
[26., 31., 43., 45., 48., 49.]])而且,事实上这个速度是相当快的。正如你所看到的,即使在1000x1000矩阵中,它也足够快。
In [68]: %timeit convolve2d(input_matrix, kernel, 'valid')
5.24 µs ± 21.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
In [69]: input = np.random.randint(10, size=(1000, 1000))
In [70]: %timeit convolve2d(input_matrix, kernel, 'valid')
41.6 ms ± 555 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)Stack Overflow用户
发布于 2022-05-07 18:56:15
@trenixjetix的convolve2d解决方案与@n-ata的总和的numpy实现相对应的微基准。即使对于相对较小的内核,第二种方法也要快得多。
import numpy as np
from scipy.signal import convolve2d
def partial_sum(array1, n):
array1 = array1.cumsum(1).cumsum(0)
res = array1.copy()
res[:,n:] -= array1[:,:-n]
res[n:] -= array1[:-n]
res[n:,n:] += array1[:-n,:-n]
return res[n-1:,n-1:]
rows = 500
cols = 500
n = 50 # relatively small n, since convolve2d becomes slow
np.random.seed(42)
array1 = np.random.randint(10, size=(rows, cols))
%timeit convolve2d(array1, np.ones((n,n), int), 'valid')
#1 loop, best of 5: 1.3 s per loop
%timeit partial_sum(array1, n)
#100 loops, best of 5: 3.36 ms per loop通过与partial_sum结果的比较,验证了convolve2d的正确性。
np.testing.assert_equal(partial_sum(array1, n), convolve2d(array1, np.ones((n,n), int), 'valid'))增长n的运行时复杂性
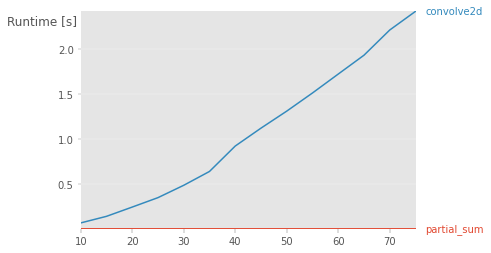
用于此基准测试的代码
import perfplot
perfplot.show(
setup=lambda n: (np.random.randint(10, size=(500, 500)), n),
kernels=[
lambda a, n: partial_sum(a, n),
lambda a, n: convolve2d(a, np.ones((n,n), int), 'valid')
],
labels=['partial_sum','convolve2d'],
n_range=[k for k in range(10,80,5)]
)Stack Overflow用户
发布于 2022-05-07 15:32:51
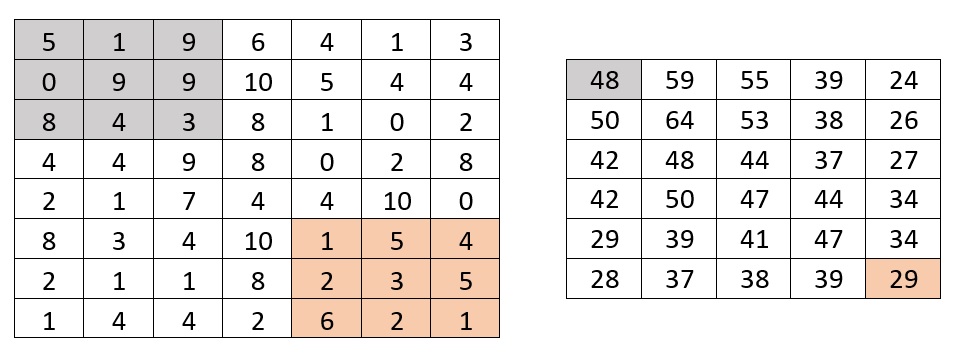
在这里你应该用部分和。你可以在一次手术中找到任何一个点。
如果您将它用于小数字。没有很大的性能差异。但是如果你用大的数字来检查它。您将看到性能差异。
行=行计数
cols =cols计数
innerrow =您的目标行。*//in your example(3)*
innercol =您的目标。*//in your example(3)*
使用您的代码:
O(rows x cols x innerrow x innercol)
O(2000 x 2000 x 200 x 2000)
但你可以用:
O(rows x cols)
示例:O(2000 x 2000)
import numpy as np
rows = 1000
cols = 2000
array1 = np.random.randint(10, size=(rows, cols))
array0 = array1
print(array1)
array2 = np.zeros((rows-100, cols-100))
for i in range(0, rows):
for j in range(1, cols):
array1[i][j] += array1[i][j-1]
for i in range(0, cols):
for j in range(1, rows):
array1[j][i] += array1[j-1][i]
for i in range(rows-100):
for j in range(cols-100):
sm = array1[i+100][j+100]
if i-1 >= 0:
sm -= array1[i-1][j+100]
if j-1 >= 0:
sm -= array1[i+100][j-1]
if i-1 >= 0 and j-1 >= 0:
sm += array0[i-1][j-1]
array2[i, j] = sm
print("output\n", array2)这是输出
[[1 9 1 9 2 0 3 8]
[7 1 8 7 1 2 8 4]
[7 1 5 4 8 3 9 0]
[4 4 8 9 3 1 7 6]
[2 5 9 9 3 6 7 2]
[9 0 9 5 0 3 2 8]]
output
[[40. 45. 45. 36. 36. 37.]
[45. 47. 53. 38. 42. 40.]
[45. 54. 58. 46. 47. 41.]
[50. 58. 55. 39. 32. 42.]]https://stackoverflow.com/questions/72153725
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号