
向熊猫加载半结构化数据
向熊猫加载半结构化数据
提问于 2022-05-03 04:39:45
我有这样的数据(来自jq)
script_runtime{application="app1",runtime="1651394161"} 1651394161
folder_put_time{application="app1",runtime="1651394161"} 22
folder_get_time{application="app1",runtime="1651394161"} 128.544
folder_ls_time{application="app1",runtime="1651394161"} 3.868
folder_ls_count{application="app1",runtime="1651394161"} 5046dataframe应该允许对每一行进行操作:
script_runtime,app1,1651394161,1651394161
folder_put_time,app1,1651394161,22它在文本文件中。我怎样才能轻松地将它加载到熊猫中进行数据处理呢?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-03 05:45:24
- 使用pd.read_csv()加载.txt,指定一个空格作为分隔符(similar StackOverflow answer)。结果将是两列数据,第一列中有方括号的文本,第二列中有浮点。
df = pd.read_csv("textfile.txt", header=None, delimiter=r"\s+")- 将括号内的文本分解为单独的列:
df['function'] = df[0].str.split("{",expand=True)[0]
df['application'] = df[0].str.split("\"",expand=True)[1]
df['runtime'] = df[0].str.split("\"",expand=True)[3]其结果是数据文件如下所示:
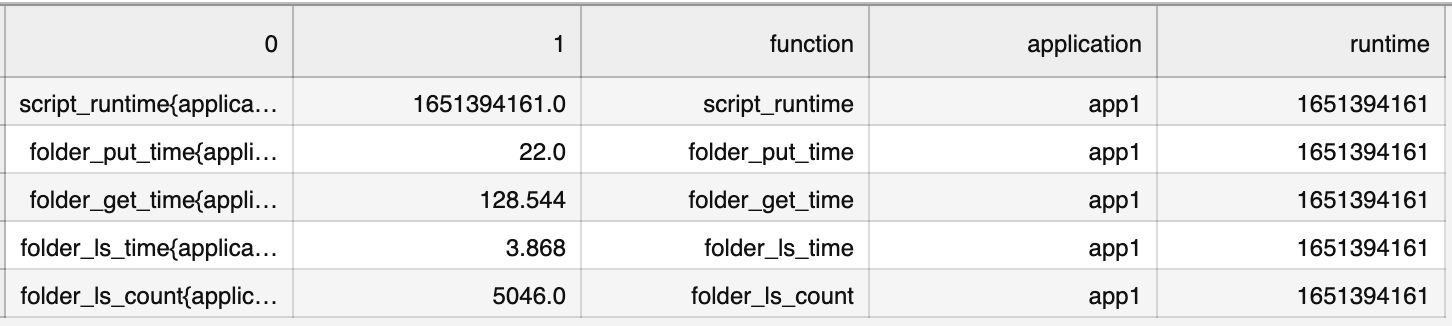
如果要删除包含括号内值的第一列:
df = df.iloc[: , 1:]

完整代码:
df = pd.read_csv("textfile.txt", header=None, delimiter=r"\s+")
df['function'] = df[0].str.split("{",expand=True)[0]
df['application'] = df[0].str.split("\"",expand=True)[1]
df['runtime'] = df[0].str.split("\"",expand=True)[3]
df = df.iloc[: , 1:]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72094860
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号