
如何实现熊猫的以下逻辑?
如何实现熊猫的以下逻辑?
提问于 2022-05-02 14:29:21
我的初始数据看起来如下:
import pandas as pd
data = {'document':['abc','abc','abc','abc','xyz','xyz','xyz','test','test','test','test','test','test','test','test','test','stackover','stackover','stackover','stackover','stackover'],
'version':[1,2,3,4,1,2,3,1,2,3,4,5,6,7,8,9,3,4,5,6,7],
'status': [100,100,100,16,200,200,11,11,11,11,15,15,11,15,15,15,10,10,100,15,10]}
df = pd.DataFrame(data)
df现在我要加上“红绿灯”栏。单元格的条件格式只用于更好的可视化:
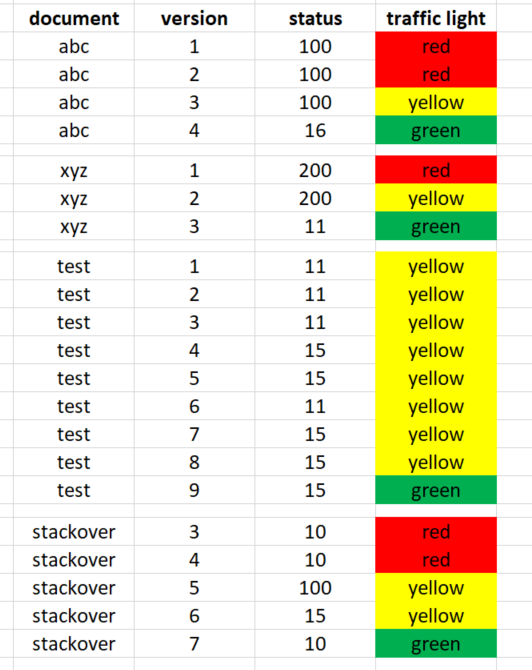
交通灯的颜色如下:
“状态”100或200:这意味着文档已经发布。
所有其他“状态”(例如16或10):未释放
green:最高的文档版本必须是值“绿色”
red:发布了一个更高的版本(状态100或200)。
黄色:有一个更高的版本没有发布(不是状态100或200)。
这能直接用熊猫的功能来实现吗?或者我需要做些什么呢?也许最好的做法是先构建黄色和红色的逻辑,然后设置最高版本的绿色或?
回答 3
Stack Overflow用户
回答已采纳
发布于 2022-05-02 14:53:07
尝试使用numpy.select
import numpy as np
#get maximum version for each document: green
green = df["version"].eq(df.groupby("document")["version"].transform("max"))
#get maximum version for each document with released status: red
red = df["version"].lt(df["document"].map(df[df["status"].isin([100,200])].groupby("document")["version"].max()))
df["traffic light"] = np.select([green, red], ["green", "red"], "yellow")
>>> df
document version status traffic light
0 abc 1 100 red
1 abc 2 100 red
2 abc 3 100 yellow
3 abc 4 16 green
4 xyz 1 200 red
5 xyz 2 200 yellow
6 xyz 3 11 green
7 test 1 11 yellow
8 test 2 11 yellow
9 test 3 11 yellow
10 test 4 15 yellow
11 test 5 15 yellow
12 test 6 11 yellow
13 test 7 15 yellow
14 test 8 15 yellow
15 test 9 15 green
16 stackover 3 10 red
17 stackover 4 10 red
18 stackover 5 100 yellow
19 stackover 6 15 yellow
20 stackover 7 10 greenStack Overflow用户
发布于 2022-05-02 14:56:34
IIUC,您可以使用:
# make group
g = df.assign(released=df['status'].isin([100,200])).groupby('document')
# get green values
green = df['version'].eq(g['version'].transform('max'))
# get next release
next_released = g['released'].apply(lambda s: s[::-1].cummax().shift(1, fill_value=False)[::-1])
# select values
import numpy as np
df['traffic light'] = np.select([green, next_released], ['green', 'red'], 'yellow')产出:
document version status traffic light
0 abc 1 100 red
1 abc 2 100 red
2 abc 3 100 yellow
3 abc 4 16 green
4 xyz 1 200 red
5 xyz 2 200 yellow
6 xyz 3 11 green
7 test 1 11 yellow
8 test 2 11 yellow
9 test 3 11 yellow
10 test 4 15 yellow
11 test 5 15 yellow
12 test 6 11 yellow
13 test 7 15 yellow
14 test 8 15 yellow
15 test 9 15 green
16 stackover 3 10 red
17 stackover 4 10 red
18 stackover 5 100 yellow
19 stackover 6 15 yellow
20 stackover 7 10 greenStack Overflow用户
发布于 2022-05-02 15:38:04
这是一个逐步添加2列的解决方案:
import pandas as pd
import numpy
data = {'document':['abc','abc','abc','abc','xyz','xyz','xyz','test','test','test','test','test','test','test','test','test','stackover','stackover','stackover','stackover','stackover'],
'version':[1,2,3,4,1,2,3,1,2,3,4,5,6,7,8,9,3,4,5,6,7],
'status': [100,100,100,16,200,200,11,11,11,11,15,15,11,15,15,15,10,10,100,15,10]}
df = pd.DataFrame(data)
df['max version'] = df.groupby('document')['version'].transform('max')
df['max release version'] = df.loc[df["status"]>=100].groupby(['document'])['version'].transform('max')
df['max release version'] = df.groupby('document')['max release version'].transform('max')
df['traffic light'] = numpy.where( df['version']==df['max version'], 'green',
numpy.where( (df['max release version'].isnull())
| ((df['max release version']==df['version'])&(df['version']!=df['max version'])), 'yellow',
numpy.where( df['version']!=df['max release version'], 'red',
numpy.nan)))
df您可以删除这些列:
df.drop(['max version','max release version'], axis='columns', inplace=True)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72088205
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号