
如何处理丢失的数据?信息将用于数据可视化。
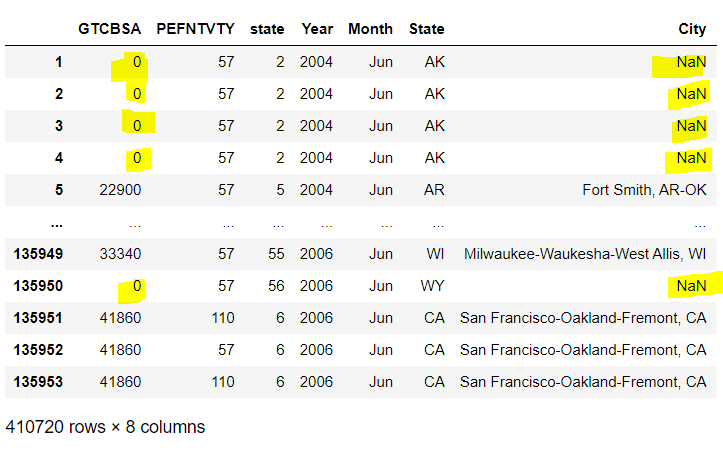
每个人如何处理dataframe中缺少的值?我通过使用人口普查网络Api来获取数据来创建数据。“GTCBSA”变量提供了城市信息,这是我使用它(平缓和破折号)所必需的,我发现数据中有很多缺失的值。我只是把它保留为空白并继续我的数据可视化吗?以下是我的变量
2004年的示例数据= https://api.census.gov/data/2004/cps/basic/jun?get=GTCBSA,PEFNTVTY&for=state:*
变量描述= https://api.census.gov/data/2022/cps/basic/jan/variables/GTCBSA.json
回答 1
Stack Overflow用户
发布于 2022-04-30 15:38:34
根据用例和缺少的数据类型,有不同的处理丢失的数据方法。例如,对于具有某些缺失值的接近连续的timeseries信号数据流,您可以尝试通过执行某种类型的插值(例如,线性插值),根据附近的值填充缺失的值。
但是,在您的情况下,缺少的值是城市,行都是独立的(每一行都是不同的应答者)。据我所知,您没有任何方法可以合理地推断出城市中缺少的行,因此您将不得不从考虑中删除这些行。
我不是美国人口普查使用的数据收集方法方面的专家,但从本源来看,似乎使用了多种方法,因此我可以看出,如何可能不知道被访者所在的城市(在线工具可能无法获得被访者所在的城市,或者被访者可能拒绝陈述自己的城市)。缺少数据是一个很常见的问题。
但是,在删除所有缺少城市的行之前,您可以做一个简短的检查,看看是否有任何模式(例如,缺少城市的行主要来自一个州吗?)如果您正在进行任何州级分析,则可以保留缺少城市的行。
https://stackoverflow.com/questions/72063211
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号