
使用BS4通过多个URL进行itterate,并将结果存储为csv格式。
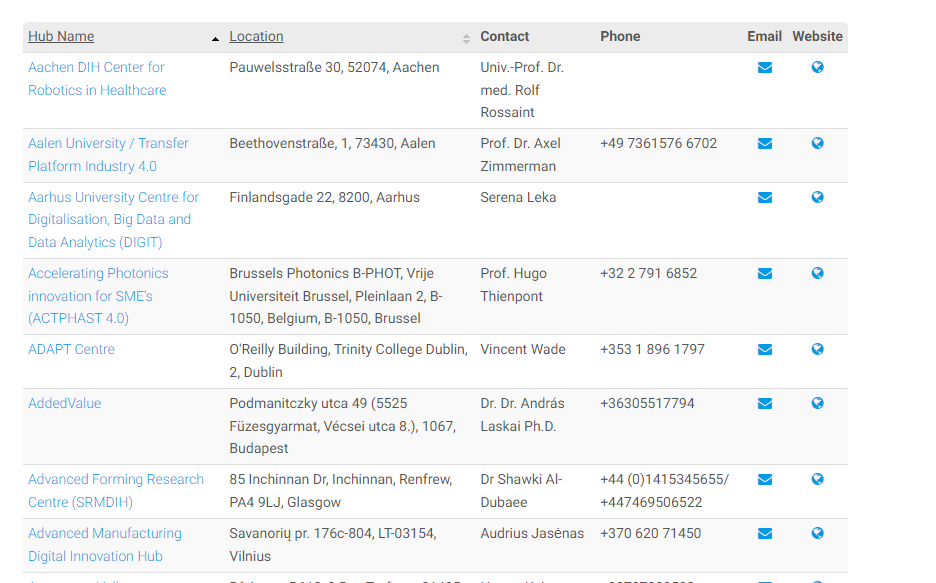
嗨,我现在正在做一个小小的sraper,我把一些片段放在一起,我有一个网址,它保存着所谓的数字集线器的记录:参见https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view。
我想以csv-格式导出700个规则:即-into,一个excel-电子表格。到目前为止还不错:
我做了一些初步的实验--看起来很不错。
看见
# Python program to print all heading tags
import requests
from bs4 import BeautifulSoup
# scraping a the content
url_link = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
request = requests.get(url_link)
Soup = BeautifulSoup(request.text, 'lxml')
# creating a list of all common heading tags
heading_tags = ["h1", "h2", "h3", "h4"]
for tags in Soup.find_all(heading_tags):
print(tags.name + ' -> ' + tags.text.strip())它提供:
h1 -> Smart Specialisation Platform
h1 -> Digital Innovation Hubs
Digital Innovation Hubs
h2 -> Bavarian Robotic Network (BaRoN) Bayerisches Robotik-Netzwerk, BaRoN
h4 -> Contact Data
h4 -> Description
h4 -> Link to national or regional initiatives for digitising industry
h4 -> Market and Services
h4 -> Organization
h4 -> Evolutionary Stage
h4 -> Geographical Scope
h4 -> Funding
h4 -> Partners
h4 -> Technologies我想得到数据集:https://s3platform.jrc.ec.europa.eu/digital-innovation-hubs-tool:我需要itterate 700个urls
https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/17865/view https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1416/view
好吧,对于这个特别的部分,我想我可以这样迭代多个URLs,我可以预先定义它,使用请求和BeautifulSoup:附件是我到目前为止所拥有的,也就是试图把URls放在一个列表中.
import requests
import bs4
URLs = ["https://example-url-1.com", "https://example-url-2.com"]
result = requests.get(URLs)
soup = bs4.BeautifulSoup(result.text,"lxml")
print(soup.find_all('p'))坦率地说:我也在寻找一种包括间隔延迟的方法,以避免垃圾邮件服务器。所以我可以这样做:
import requests
import bs4
import sleep from time
URLs = ['https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view',
'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/17865/view',
'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1416/view'
]
def getPage(url):
print('Indexing {0}......'.format(url))
result = requests.get(url)
print('Url Indexed...Now pausing 50secs before next ')
sleep(50)
return result
results = map(getPage, URLs)
for result in results:
# soup = bs4.BeautifulSoup(result.text,"lxml")
soup = bs4.BeautifulSoup(result.text,"html.parser")
print(soup.find_all('p'))现在对于解析器-部分:解析数据(如这里的示例:https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view )。
import requests
from bs4 import BeautifulSoup
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
html_as_string = r.text
soup = BeautifulSoup(html_as_string, 'html.parser')
for link in soup.find_all('p'):
print (link.text)结果--非常棒,但没有排序--我想以csv格式存储所有结果--这是一个包含以下列的超表:
数字创新中心巴伐利亚机器人网络( h2 -> Bavarian Robotik-Netzwerk,BaRoN h4 -> Contact Data h4 -> Description h4 -> )与国家或地区的数字化产业发展计划( h4 -> Market和Services h4 -> Organization h4 h4 -> Organization)发展阶段地理范围en24 20#资金en22 en24#技术
看见
import requests
from bs4 import BeautifulSoup
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
html_as_string = r.text
soup = BeautifulSoup(html_as_string, 'html.parser')
for link in soup.find_all('p'):
print (link.text)见结果:
如果要建议更改此集线器,请单击以下链接:
您需要一个欧盟登录帐户为新集线器的版本或创建请求建议。如果您已经有了一个ECAS帐户,则不需要创建一个新的EU登录帐户。在“欧盟登录”中,您的凭据和个人数据保持不变。您仍然可以访问与前面相同的服务和应用程序。你只要用你的电子邮件地址登录就行了。如果您没有欧盟登录帐户,请使用以下链接。您可以通过单击create超链接来创建一个。如果您已经有了EU登录的用户帐户,请在新用户中通过https://webgate.ec.europa.eu/cas/login签名登录?创建一个账户协调员(大学)慕尼黑技术大学机器人能力中心,TUM CC协调员网站,http://www6.in.tum.de/en/home/年建立了2017年Schlee海默Str。90a,85748,Garching beiünchen(德国)网站http://www.robot.bayern Social Media
联系方式: Adam adam.schmidt@tum.de +49 (0)89 289-18064
年确定2017年地点,施莱-海姆·斯特尔。90a,85748,Garching beiünchen(德国)网站http://www.robot.bayern Social Media
联系信息描述BaRoN是一项倡议,将巴伐利亚的几个行为者聚集在一起: TUM机器人能力中心,在该项目内成立,巴伐利亚研究联盟(BayFOR),ITZB (Projekttr Ger Bayern)和Bayerische Patentallianz,后者是巴伐利亚研究和创新机构的成员,以促进巴伐利亚制造业部门的机器人化进程。以目前的形式,它是一个由在巴伐利亚带来和促进创新领域具有广泛经验的常设机构组成的非正式联盟。该网络的使命是使巴伐利亚成为数字化和机器人化的欧洲工业的先驱。为实现这一使命,向巴伐利亚制造业生态系统的各个实体--初创企业、中小企业、研究机构、大学和其他有兴趣拥抱工业4.0革命的机构提供服务,包括提供技术专门知识、获得机器人设备、知识产权咨询和管理,以及提供资金便利。BaRoN逐字,mehrere,Bayerische,Akteure,mit,einem,gemeinsamen,Ziel - die Robotisierung des Bayerischen,produzierenden,Gewerbes voranzutreiben。通过建立和扩大产品和服务开发的先进能力以及通过国际化举措提高中小企业的竞争力预算1.4B欧元
假设:它正在用BS4返回一个糟糕的、未排序的数据块--如何清理Pandas,以便我有一个包含以下列的cean表
h1 -> Smart Specialisation Platform
h1 -> Digital Innovation Hubs
Digital Innovation Hubs
h2 -> Bavarian Robotic Network (BaRoN) Bayerisches Robotik-Netzwerk, BaRoN
h4 -> Contact Data
h4 -> Description
h4 -> Link to national or regional initiatives for digitising industry
h4 -> Market and Services
h4 -> Organization
h4 -> Evolutionary Stage
h4 -> Geographical Scope
h4 -> Funding
h4 -> Partners
h4 -> Technologies更新:感谢提姆·罗伯茨,我看到了我们的组合
class: hubCard
class: hubCardTitle
class: hubCardContent
class: infoLabel >Description>
<p> Text - data - content <p>有了这个-我们可以一步一步地扩展解析工作。感谢你蒂姆!

这就是说-我只是想得到其他感兴趣的领域的数据-例如。开头是这样的描述文本:
BaRoN是一项将巴伐利亚多个行为者聚集在一起的倡议: TUM机器人能力中心成立于马术项目、巴伐利亚研究联盟(BayFOR)、ITZB (Projekttr Ger Bayern)。
我把你的想法,提姆用在代码里了。-但它不起作用
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html5lib')
# The name of the hub is in the <h4> tag.
hubname = soup.find('h4').text
# All contact info is within a <div class='hubCard'>.
description = soup.find("div", class_="hubCardContent")
cardinfo = {}
# Grab all the <p> tags inside that div. The infoLabel class marks
# the section header.
for data in description.find_all('p'):
if 'infoLabel' in data.attrs.get('class', []):
Description = data.text
cardinfo[Description] = []
else:
cardinfo[Description].append( data.text )
# The contact info is in a <div> inside that div.
#for data in contact.find_all('div', class_='infoMultiValue'):
# cardinfo['Description'].append( data.text)
print("---")
print(hubname)
print("---")
pprint(cardinfo)它总是返回内容信息--但不是我正在寻找的数据--描述的文本:我做错了什么.
回答 1
Stack Overflow用户
发布于 2022-04-25 20:21:09
也许这能给你一个开始。您必须深入到HTML中,才能找到所需信息的关键标记。我感觉到你想要标题和联系信息。标题位于<h2>标记中,这是页面上唯一这样的标记。联系信息是在一个<div class='hubCard'>标签内,所以我们可以抓取和取出碎片。
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://s3platform-legacy.jrc.ec.europa.eu/digital-innovation-hubs-tool/-/dih/1096/view'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html5lib')
# The name of the hub is in the <h2> tag.
hubname = soup.find('h2').text
# All contact info is within a <div class='hubCard'>.
contact = soup.find("div", class_="hubCard")
cardinfo = {}
# Grab all the <p> tags inside that div. The infoLabel class marks
# the section header.
for data in contact.find_all('p'):
if 'infoLabel' in data.attrs.get('class', []):
title = data.text
cardinfo[title] = []
else:
cardinfo[title].append( data.text )
# The contact info is in a <div> inside that div.
for data in contact.find_all('div', class_='infoMultiValue'):
cardinfo['Contact information'].append( data.text)
print("---")
print(hubname)
print("---")
pprint(cardinfo)输出:
---
Bavarian Robotic Network (BaRoN) Bayerisches Robotik-Netzwerk, BaRoN
---
{'Contact information': [' Adam Schmidt',
' adam.schmidt@tum.de',
' +49 (0)89 289-18064'],
'Coordinator (University)': ['',
'Robotic Competence Center of Technical '
'University of Munich, TUM CC'],
'Coordinator website': ['http://www6.in.tum.de/en/home/\n'
'\t\t\t\t\t\n'
'\t\t\t\t\t\n'
'\t\t\t\t\t'],
'Location': ['Schleißheimer Str. 90a, 85748, Garching bei München (Germany)'],
'Social Media': ['\n'
'\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t\t\t\t\t \n'
'\t\t\t\t\t\t\t\t\t\t\n'
'\t\t\t\t\t\t'],
'Website': ['http://www.robot.bayern'],
'Year Established': ['2017']}https://stackoverflow.com/questions/72004129
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号