
熊猫数据的for-if循环语句操作的问题
我有一个数据集,我想要创建一个新的列,它是基于使用if-条件的for-循环的另外两个列的除法。
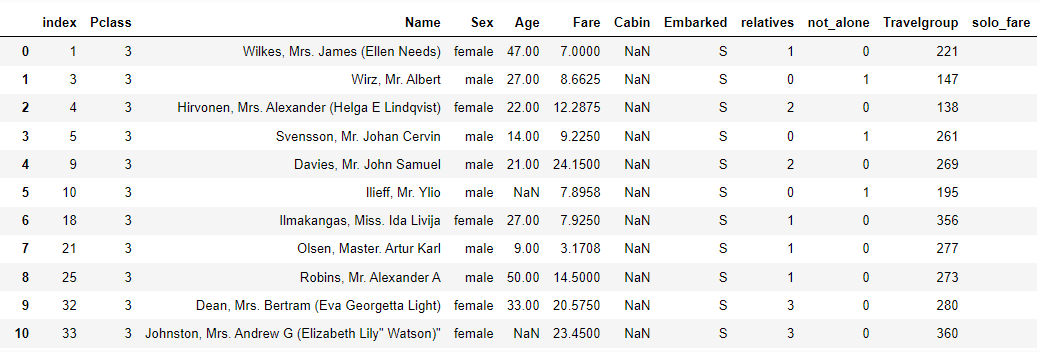
这是dataset,空的'solo_fare‘列是预先创建的。
其任务是遍历每一行,并将“票价”除以“亲属”,以获得每名乘客的票价。然而,也有一定的假设条件需要遵循(这类乘客应该看到3到8之间的每个乘客价格)。
我在这里尝试过的代码似乎根本没有填写“solo_fare”行。它返回一个空列(与上面的df相同)。
for i in range(0, len(fare_result)):
p = fare_result.iloc[i]['Fare']/fare_result.iloc[i]['relatives']
q = fare_result.iloc[i]['Fare']
r = fare_result.iloc[i]['relatives']
# if relatives == 0, return original Fare amount
if (r == 0):
fare_result.iloc[i]['solo_fare'] = q
# if the divided fare is below 3 or more than 8, return original Fare amount again
elif (p < 3) or (p > 8):
fare_result.iloc[i]['solo_fare'] = q
# else, return the divided fare to get solo_fare
else:
fare_result.iloc[i]['solo_fare'] = p 我怎么才能让这个起作用?
回答 3
Stack Overflow用户
发布于 2022-04-25 07:20:51
您可能不应该为此使用循环,而应该使用loc。
如果您首先创建“单人车费”列,并为每行提供票价的默认值,则可以更改所列出的条件的值。
fare_result['solo_fare'] = fare_result['Fare']
fare_results.loc[(
(fare_results.Fare / fare_results.relatives) >= 3) & (
(fare_results.Fare / fare_results.relatives) <= 8), 'solo_fare'] = (
fare_results.Fare / fare_results.relatives)Stack Overflow用户
发布于 2022-04-25 07:13:08
你试过先初始化那些新列吗?
我的意思是,语句fare_result.iloc[i]['solo_fare'] = q仅意味着将值q赋值给第1行的字段solo_fare。
现在的问题是,我的行没有任何solo_fare密钥。因此,您只在这里填充表的最后一个值。
要解决此问题,请在for循环之前声明solo_fare列,如下所示:
fare_result['solo_fare'] = np.nanStack Overflow用户
发布于 2022-04-25 08:16:14
一种方法是定义一个逐行函数,并将其应用于dataframe:
# row-wise function (mockup)
def foo(fare, relative):
# your logic here. Mine just serves as example
if relative > 100:
res = fare/relative
elif (relative < 10):
res = fare
else:
res = 10
return res然后将其应用于dataframe (逐行):
fare_result['solo_fare'] = fare_result.apply(lambda row: foo(row['Fare'], row['relatives']) , axis=1)https://stackoverflow.com/questions/71995560
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号