
数据集时间窗口
我在此表单下有一个数据集
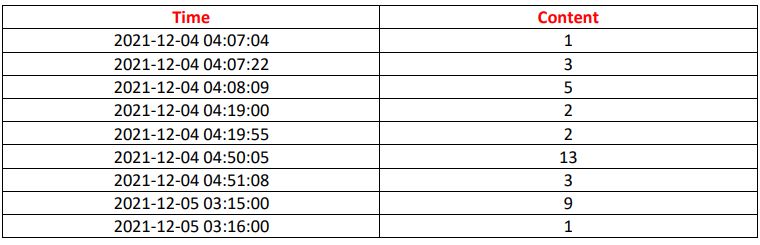
我想通过创建一个窗口来分割数据集,其中包括每2分钟发生一次的行,然后我将将结果包含在另一个数据集中,该数据集将在此表单下。
我在问是否有人能帮我加速我的工作?
回答 2
Stack Overflow用户
发布于 2022-04-22 22:43:57
下面是一个随机数据,df:
df:
Content
Date
2021-12-04 04:07:04 6
2021-12-04 04:07:20 1
2021-12-04 04:08:04 4
2021-12-04 04:09:04 12
2021-12-04 04:12:04 4
2021-12-04 04:15:04 8
2021-12-04 04:15:04 10
2021-12-04 04:16:04 4
2021-12-04 04:17:04 6
2021-12-04 04:17:24 3现在,我将使用pd.Grouper的‘2分钟’频率和apply(list)
df_out= df.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list).df_out:
Date
2021-12-04 04:06:00 [6, 1]
2021-12-04 04:08:00 [4, 12]
2021-12-04 04:10:00 []
2021-12-04 04:12:00 [4]
2021-12-04 04:14:00 [8, 10]
2021-12-04 04:16:00 [4, 6, 3]如果要将第二列作为列表,则使用.tolist()
list=df_out.tolist()
list:
[[6, 1], [4, 12], [], [4], [8, 10], [4, 6, 3]]要获取每个元素,请使用df_out[i] # i=0,1,2等,如果要将其转换为数据框架,则使用pd.DataFrame(df_out)
请记住,如果您从csv或其他文件中读取文本文件,则必须使用以下方法将df索引转换为日期时间索引:
df.index = pd.to_datetime(df.index)测试csv文件的完整代码:
import pandas as pd
df=pd.read_csv(r'D:\python\test.txt', sep=',').set_index('Date')
df.index = pd.to_datetime(df.index)
df_out= df.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list)如果您不知道如何创建一个示例df,这里我再举一个例子:
import pandas as pd
import numpy as np
np.random.seed(0)
# create an array of 10 dates starting at '2021-12-04', one per minute
rng = pd.date_range('2021-12-04 04:07:04', periods=10, freq='T')
df_random = pd.DataFrame({ 'Date': rng, 'Content': np.random.randint(1,13,10) }).set_index('Date')
df_random_out= df_random.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list)
df_random:
Content
Date
2021-12-04 04:07:04 6
2021-12-04 04:08:04 1
2021-12-04 04:09:04 4
2021-12-04 04:10:04 12
2021-12-04 04:11:04 4
2021-12-04 04:12:04 8
2021-12-04 04:13:04 10
2021-12-04 04:14:04 4
2021-12-04 04:15:04 6
2021-12-04 04:16:04 3
df_random_out:
Date
2021-12-04 04:06:00 [6]
2021-12-04 04:08:00 [1, 4]
2021-12-04 04:10:00 [12, 4]
2021-12-04 04:12:00 [8, 10]
2021-12-04 04:14:00 [4, 6]
2021-12-04 04:16:00 [3]注:请解释清楚你想对你的结果做些什么,这样我就可以相应地回答。
Stack Overflow用户
发布于 2022-04-22 22:57:38
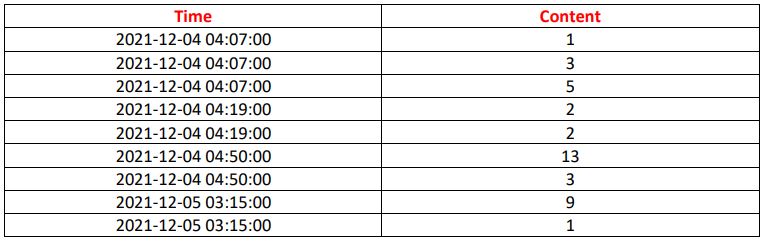
这花了我一些时间,我发布了一个回复,但当我意识到它不同于预期的result...also时,我删除了它,在@Shuvashish上取了一段--申请(列表)。但是anyways..this应该给出预期的结果:
df['Time']=pd.to_datetime(df['Time'])
df.set_index('Time',inplace=True)
df2=pd.DataFrame(df.groupby(pd.Grouper(freq='2Min',origin=df.index[0].floor('Min')))['Content'].apply(list).explode())
df2[df2.Content.notna()].reset_index()Shuvashish已经显示了pd.Grouper -我只是爆炸了结果,并将原点设置为第一次值“溢出”到分钟-顺便说一下,不应该有04:50:00的时间,因为我们从奇数04:07:00开始每2分钟一次。
https://stackoverflow.com/questions/71973791
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号