
无法使用urllib.request从网站下载文件
无法使用urllib.request从网站下载文件
提问于 2022-04-19 17:49:44
我试图使用python urllib.request库从字母表网站下载.pdb (蛋白质数据库)文件,其中包含给定蛋白质的全部预测分子结构。在本例中,我试图下载一个带有uniprot的Q9BY15的蛋白质。条目https://alphafold.ebi.ac.uk/entry/Q9BY15包含到蛋白质的pdb文件的下载链接,如下所示;

所述手动下载的文件具有以下命名格式;
下面是我正在使用的代码块(最简单的形式)
import os
import urllib
import urllib.request
url = 'https://alphafold.ebi.ac.uk/entry/'
prot = 'Q9BY15'
alphaname = 'AF-' + prot + '-F1-model_v2.pdb'
urllib.request.urlretrieve(url + prot, alphaname)这是我在运行代码时得到的文件;
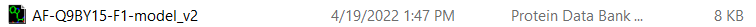
正如您所看到的,该文件比实际文件的实际大小要小得多(尽管名称完全相同),并且在通过蛋白质识别程序查看它时实际上是空的。我将如何重写这段代码来提取实际文件?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-04-19 17:57:26
我不确定这是否能解决您的问题,但是下载Q9BY15的pdb文件的正确的url是https://alphafold.ebi.ac.uk/files/AF-Q9BY15-F1-model_v2.pdb
尝试将链接中的/entry/替换为/files/。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71929212
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号