
无法从Glue ETL作业写入湖泊形成治理表数据
我正在构建一个POC与湖泊形成,在这里,我读取队列的列车运动信息,并将个别事件持久化到一个受治理的表使用AWS数据游泳者。这个很好用。
然后我尝试用AWS Glue ETL作业读取这个受治理的表,并将结果数据写入另一个受治理的表中。这是成功的,并将拼花文件写入该表的S3桶/文件夹中,但当我尝试查询数据时,它无法从雅典娜读取(雅典娜查询只是不返回记录)。
我使用以下Aws Wrangler语句创建了the表:
aw.catalog.create_parquet_table(database = "train_silver",
table = "journey",
path = "s3://train-silver/journey/",
columns_types = {
'train_id': 'string',
'date': 'date',
'stanox': 'string',
'start_timestamp': 'timestamp',
'created': 'timestamp',
'canx_timestamp': 'bigint'
},
compression = "snappy",
partitions_types = {'segment_date': 'date'},
table_type = "GOVERNED")以下是Glue作业的代码:
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
logger = glueContext.get_logger()
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
logger.info('About to start transaction')
tx_id = glueContext.start_transaction(False)
bronze_table = glueContext.create_dynamic_frame.from_catalog(database = "train_bronze", table_name = "train_movements_governed",
additional_options = { "transactionId": tx_id })
logger.info('About to save the bronze table to a view')
bronze_table.toDF().registerTempTable("train_movements")
max_journey_timestamp = 0
journey_df = spark.sql("""
SELECT train_id, loc_stanox as stanox, CAST(canx_timestamp as bigint) AS canx_timestamp, segment_date
FROM train_movements
WHERE canx_type = 'AT ORIGIN'
AND cast(canx_timestamp AS bigint) > {}""".format(max_journey_timestamp))
journey_df = journey_df.withColumn("created",current_timestamp())
def date_from_timestamp(timestamp_int):
return datetime.fromtimestamp(int(timestamp_int) / 1000.0).date()
date_UDF = udf(lambda z: date_from_timestamp(z))
def date_time_from_timestamp(timestamp_int):
return datetime.fromtimestamp(int(timestamp_int) / 1000.0)
date_time_UDF = udf(lambda z: date_from_timestamp(z))
journey_df = journey_df.withColumn("date", date_UDF(col("canx_timestamp")))
journey_df = journey_df.withColumn("start_timestamp", date_time_UDF(col("canx_timestamp")))
journey_df.printSchema()
try:
save_journey_frame = DynamicFrame.fromDF(journey_df, glueContext, "journey_df")
logger.info('Saving ' + str(save_journey_frame.count()) + 'new journeys')
journeySink = glueContext.write_dynamic_frame.from_catalog(frame = save_journey_frame, database = "train_silver", table_name = "journey",
additional_options = { "callDeleteObjectsOnCancel": True, "transactionId": tx_id })
logger.info('Committing transaction')
glueContext.commit_transaction(tx_id)
logger.info('Transaction committed')
except Exception:
glueContext.cancel_transaction(tx_id)
raise
logger.info('Committing the job')
job.commit()在运行Glue作业时,表文件夹中有拼板文件,但它们不是在我的表定义定义的分区文件夹中组织的:
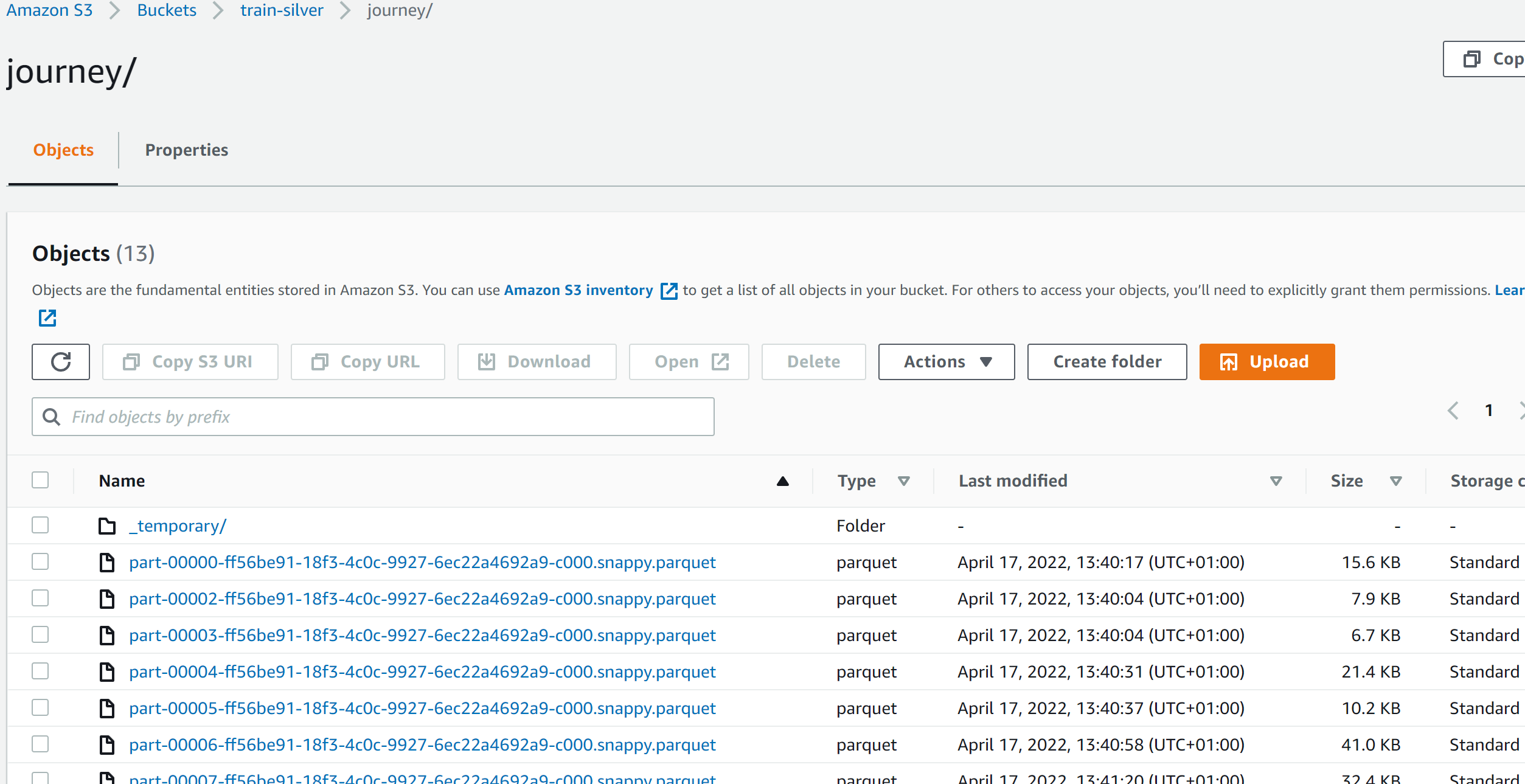
我还试着编写一个胶水作业来读取文件夹中的拼花文件,它们包含了它们应该包含的所有行。
下面是我试图查询雅典娜的数据的截图:
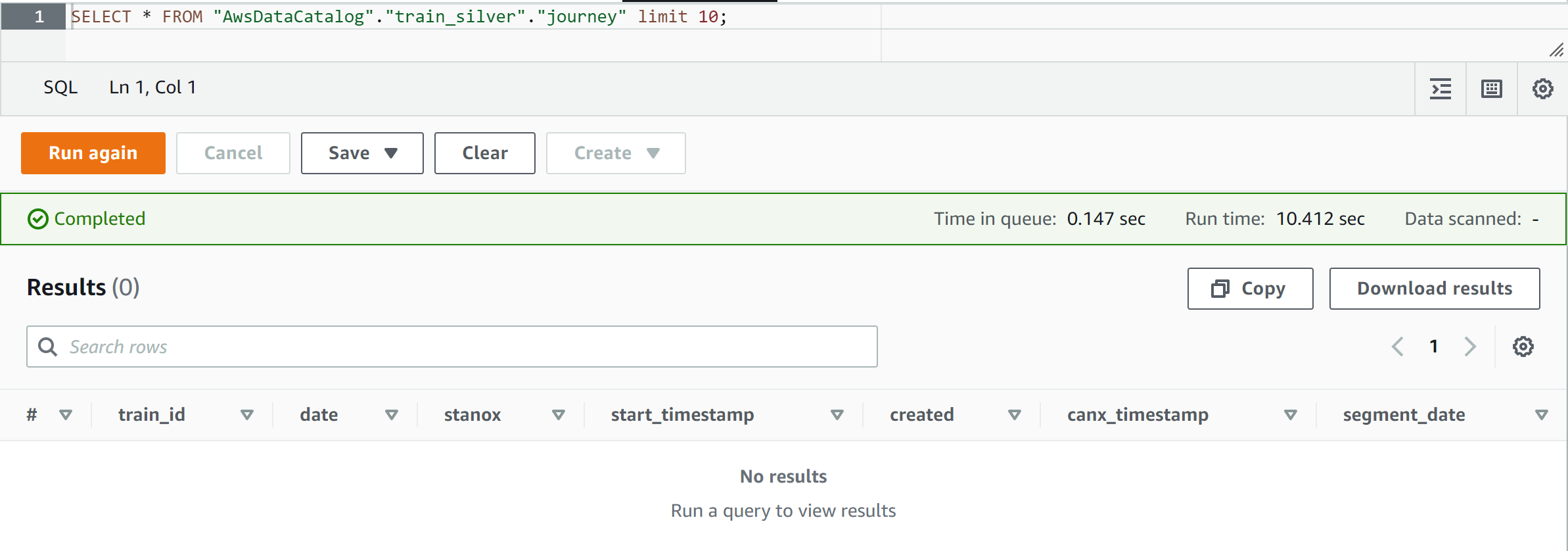
我在这里遗漏了什么,如何从Spark胶水作业中将数据添加到治理表中,这样我就可以从雅典娜那里查询它了?
回答 1
Stack Overflow用户
发布于 2022-07-16 08:38:26
我认为问题在于表上的对象没有被更新。
您可以使用这个AWS命令来检查它:
aws lakeformation get-table-objects --database-name train_silver --table-name journey对于编写Apache,AWS Glue ETL只支持通过为动态框架优化的自定义Parquet编写器类型指定一个选项来写入受治理的表。当用拼花格式写入受治理的表时,应该在表参数中添加值为true的键useGlueParquetWriter。
您也可以在创建表时将表的分类参数设置为“胶合板”(也可以更新此参数):
aw.catalog.create_parquet_table(database = "train_silver",
table = "journey",
path = "s3://train-silver/journey/",
columns_types = {
'train_id': 'string',
'date': 'date',
'stanox': 'string',
'start_timestamp': 'timestamp',
'created': 'timestamp',
'canx_timestamp': 'bigint'
},
compression = "snappy",
parameters={
"classification": "glueparquet"
}
partitions_types = {'segment_date': 'date'},
table_type = "GOVERNED")https://stackoverflow.com/questions/71902530
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号