
为什么当所报告的代理集的大小从2到3时,n-of显示不连续性?
n-of记者是那些随机选择的记者之一,所以我们知道,如果我们使用相同的random-seed,我们总是可以从n-of中得到相同的代理。
n-of 有两个论点:size和agentset (它也可以列出列表,但稍后会对此进行说明)。我希望它可以通过抛出一个伪随机数,使用这个数字从agentset中选择一个代理,并重复这个过程size次数。
如果这是真的,那么如果我们在相同的代理集上测试并使用相同的random-seed,但是每次将大小增加1时,每个产生的代理集都将与前面的提取中的相同,再加上一个进一步的代理。毕竟,用于选择第一个(size - 1)代理的伪随机数序列与以前相同。
这似乎得到了普遍的证实。下面的代码突出显示相同的补丁,再加上每次增加大小时再加一个补丁,如图所示:
to highlight-patches [n]
clear-all
random-seed 123
resize-world -6 6 -6 6
ask n-of n patches [
set pcolor yellow
]
ask patch 0 0 [
set plabel word "n = " n
]
end


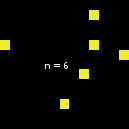
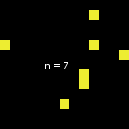
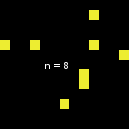
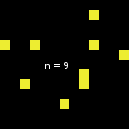
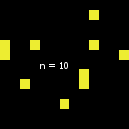
但也有一个例外:当size从2变为3时,情况就不一样了。如下图所示,n-of在从size 1开始时似乎遵循了通常的行为,但当size达到3(成为上述数字的代理集--据我所知,这种行为不再改变)时,代理集就会突然发生变化:


在n-of的幕后到底发生了什么,在这个看似无法解释的门槛上导致了这种变化?
特别是,这似乎只适用于n-of。事实上,结合使用repeat和one-of并没有显示出这种不连续性(至少就我所见过的情况而言):
to highlight-patches-with-repeat [n]
clear-all
random-seed 123
resize-world -6 6 -6 6
repeat n [
ask one-of patches [
set pcolor yellow
]
]
ask patch 0 0 [
set plabel word "n = " n
]
end





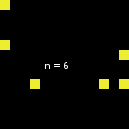


请注意,这种比较不受以下事实的影响:n-of保证没有重复,而repeat + one-of可能有重复(在我前面的示例中,第一次重复发生在大小达到13时)。相关的方面只是,报告的size x代理集与报告的sizex+ 1代理集是一致的。
关于在列表中使用n-of而不是代理集
在列表上执行相同的操作会导致总是提取不同的数字,也就是说,附加提取并不等于先前的提取,而是添加了另一个数字。虽然在我看来,这是一种违反直觉的行为,从一个角度来看,如果提取总是基于相同的伪随机数序列,那么期望从列表中提取的项目总是相同的,至少它看起来是一致的,因此在我看来,它不像代理集那样模棱两可的行为。
回答 1
Stack Overflow用户
发布于 2022-04-12 21:46:14
所以让我们来看看这是如何一起工作的。让我们首先检查基本实现本身。它住在这里。下面是具有错误处理和注释的相关位(为简洁起见):
if (obj instanceof LogoList) {
LogoList list = (LogoList) obj;
if (n == list.size()) {
return list;
}
return list.randomSubset(n, context.job.random);
} else if (obj instanceof AgentSet) {
AgentSet agents = (AgentSet) obj;
int count = agents.count();
return agents.randomSubset(n, count, context.job.random);
}因此,我们需要研究列表和代理集的randomSubset()实现。我先从代理开始。
实现就在这里。以及相关的双边投资条约:
val array: Array[Agent] =
resultSize match {
case 0 =>
Array()
case 1 =>
Array(randomOne(precomputedCount, rng.nextInt(precomputedCount)))
case 2 =>
val (smallRan, bigRan) = {
val r1 = rng.nextInt(precomputedCount)
val r2 = rng.nextInt(precomputedCount - 1)
if (r2 >= r1) (r1, r2 + 1) else (r2, r1)
}
randomTwo(precomputedCount, smallRan, bigRan)
case _ =>
randomSubsetGeneral(resultSize, precomputedCount, rng)
}那你就去吧。我们可以看到,当resultSize是2时,有一个特例。它自动生成2个随机数,并翻转它们以确保它们不会“溢出”可能的选择。关于实现的评论澄清了这是作为一个优化做的。对于1也有类似的特例,但这只是one-of。
好吧,现在让我们核对一下清单。看起来像住在这里。这是一个片段:
def randomSubset(n: Int, rng: Random): LogoList = {
val builder = new VectorBuilder[AnyRef]
var i = 0
var j = 0
while (j < n && i < size) {
if (rng.nextInt(size - i) < n - j) {
builder += this(i)
j += 1
}
i += 1
}
LogoList.fromVector(builder.result)
}代码有点迟钝,但是对于列表中的每个元素,它都是随机地将其添加到结果子集中。如果没有添加早期的项目,那么以后的项目的可能性就会增加(如果需要的话,增加到100% )。因此,更改列表的总体大小将更改将在序列:rng.nextInt(size - i)中生成的数字。这将解释为什么在使用相同的种子但使用更大的列表时,没有按顺序选择相同的项目。
精化
好的,让我们详细介绍代理集的n = 2优化。有几件事我们必须知道来解释这一点:
- 非优化的代码是做什么的?
非优化代理集代码看起来很像我已经讨论过的列表代码-它迭代代理集中的每一项,并随机决定将其添加到结果中或不添加:
val iter = iterator
var i, j = 0
while (j < resultSize) {
val next = iter.next()
if (random.nextInt(precomputedCount - i) < resultSize - j) {
result(j) = next
j += 1
}
i += 1
}请注意,对于代理集中的每个项,这段代码将执行几个算术操作,precomputedCount - i和resultSize - j,以及最后的<比较和j和i abd的增量-- while循环的j < resultSize检查。它还为每个选中的元素(昂贵的操作)生成一个随机数,并调用next()将代理迭代器向前移动。如果它在处理代理集的所有元素之前填充结果集,它将终止“早期”并保存部分工作,但在最坏的情况下,当需要最后一个代理完全“填充”结果时,它可能会对代理集中的每个元素执行所有这些操作。
- 优化的代码是做什么的,为什么它更好?
现在让我们检查一下代码
if (!kind.mortal)
Array(
array(smallRandom),
array(bigRandom))
else {
val it = iterator
var i = 0
// skip to the first random place
while(i < smallRandom) {
it.next()
i += 1
}
val first = it.next()
i += 1
while (i < bigRandom) {
it.next()
i += 1
}
val second = it.next()
Array(first, second)
}首先,最初对kind.mortal的检查基本上是检查这是否是修补程序代理集。补丁永远不会是die,因此可以安全地假设代理集中的所有代理都是活动的,因此可以在两个提供的随机数处返回支持数组中的代理。
接下来是第二位。在这里,我们必须使用iterator从集合中获取代理,因为其中一些代理可能已经死亡(海龟或链接)。迭代器将跳过这些内容,因为我们调用next()来获取下一个代理。您可以看到这里的操作正在执行while检查,因为它通过所需的随机数将i递增。因此,这里的工作是索引器i的增量,以及对while()循环的检查。我们还必须调用next()来向前移动迭代器。这是因为我们知道smallRandom比bigRandom要小--我们只是跳过代理程序并提取出我们想要的代理。
比较我们避免了产生许多随机数的非优化版本,我们避免了有一个额外的变量来跟踪结果集计数,并且我们避免了数学和较少的检查来确定结果集中的记忆。这还不错(尤其是RNG操作)。
会产生什么影响?如果你有一个很大的代理集,比如说1000个代理,而你正在挑选其中的两个,那么挑选任何一个代理的几率都很小(实际上从1/1000开始)。这意味着在获得2种代理之前,您将运行所有这些代码很长一段时间。
那么,为什么不对n-of 3、4或5等进行优化呢?那么,让我们回顾一下运行优化版本的代码:
case 2 =>
val (smallRan, bigRan) = {
val r1 = rng.nextInt(precomputedCount)
val r2 = rng.nextInt(precomputedCount - 1)
if (r2 >= r1) (r1, r2 + 1) else (r2, r1)
}
randomTwo(precomputedCount, smallRan, bigRan)if (r2 >= r1) (r1, r2 + 1) else (r2, r1)结尾的那个小逻辑确保了smallRan < bigRan;即严格地小于,而不是相等的。当需要生成3、4或5+随机数时,该逻辑变得更加复杂。它们都不可能是一样的,它们都必须井井有条。有一些方法可以快速排序可能有用的数字列表,但是不重复地生成随机数要困难得多。
https://stackoverflow.com/questions/71811299
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号