
如何提取折扣(%折扣)值?
如何提取折扣(%折扣)值?
提问于 2022-04-09 08:07:04
我得到了想要的结果,但我不知道如何从列表中提取百分比值,因为它没有类。
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
data.append({
'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in'+ str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k='+k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
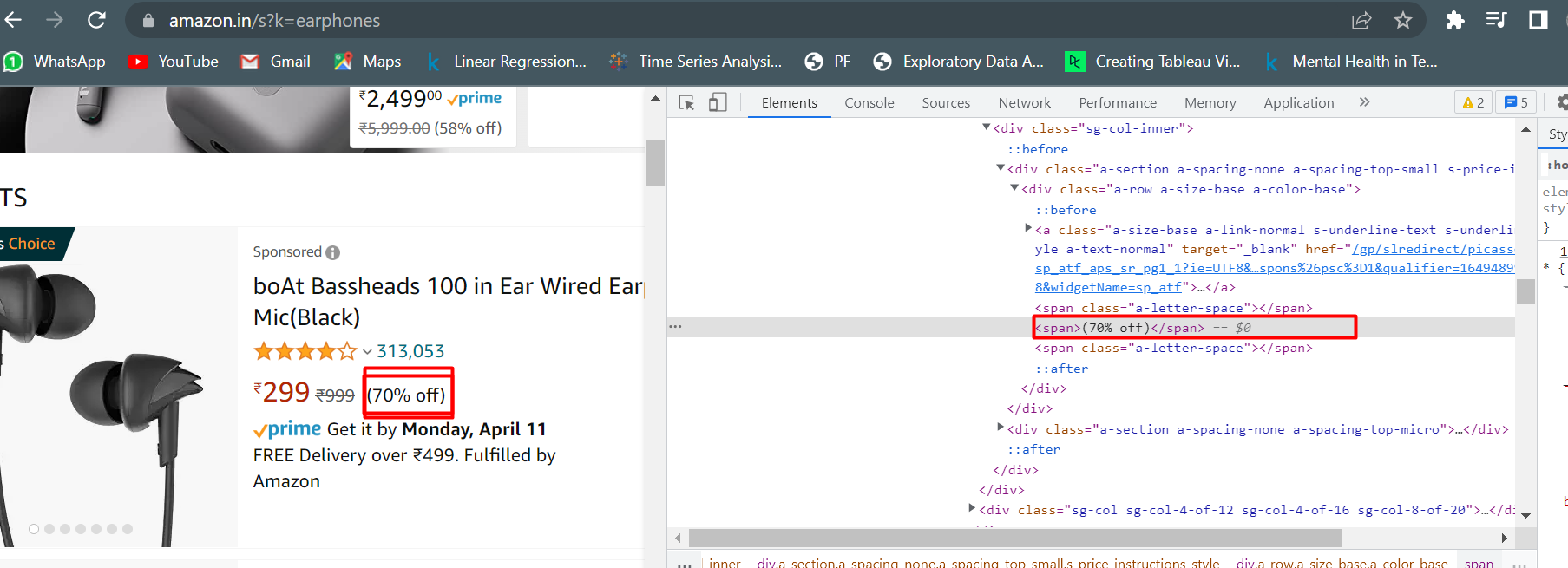
print(url)我怎样才能得到折扣(折)?我还没有为此编写任何代码,其余的结果都是正确显示的。
<
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-04-09 08:36:08
您可以从span class="a-price-whole"获得折扣价格
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
try:
list_price = e.select_one('.a-letter-space +span').text
print(list_price)
except:
limited_deal = None
data.append({
#'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in'+ str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k='+k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
#print(url)输出:
(70% off)
(56% off)
(70% off)
(70% off)
(63% off)
(25% off)
(53% off)
(50% off)
(63% off)
(43% off)
(57% off)
(62% off)
(50% off)
(60% off)
(69% off)
(50% off)
(41% off)
(60% off)
(70% off)..。等等
如果你只需要数字
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
data =[]
def getdata (url):
header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(url, headers=header)
amazon_html = urllib.request.urlopen(req).read()
a_soup = soup(amazon_html,'html.parser')
for e in a_soup.select('div[data-component-type="s-search-result"]'):
try:
title = e.find('h2').text
except:
title = None
try:
sponsored = e.find('span',{'class':'a-color-secondary'}).text
except:
sponsored = None
try:
limited_deal = e.find('span',{'class':'a-badge-label-inner a-text-ellipsis'}).find('span', {'class': 'a-badge-text'}).text
except:
limited_deal = None
try:
list_price = e.select_one('.a-letter-space +span').text.split('%')[0].replace('(','')
print(list_price)
except:
limited_deal = None
data.append({
#'list_price':list_price,
'sponsored':sponsored,
'limited_deal':limited_deal
})
return a_soup
def getnextpage(a_soup):
try:
page = a_soup.find('a',attrs={"class": 's-pagination-item s-pagination-next s-pagination-button s-pagination-separator'})['href']
url = 'http://www.amazon.in'+ str(page)
except:
url = None
return url
keywords = ['earphones']
for k in keywords:
url = 'https://www.amazon.in/s?k='+k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
#print(url)输出:
70
56
70
70
63
25
53
50
63
50
57
62
60
69
50
43
60
70
41
61
53
61
57
53
61
70
70
60
75
57
75
18
62
61
38
60
80
71
70
60
81
47
70
53
57
62
53
64
57
37
80
42
83
55
53
78
63Stack Overflow用户
发布于 2022-04-09 08:45:00
您可以使用css选择器.a-letter-space+ span和BeautifulSoup的select方法并循环遍历结果以提取折扣文本
下面是一个示例代码:
import requests
from bs4 import BeautifulSoup
def extract_discount(discount_str):
"""
Extract discount from an unformatted
discount string like: (70% off)
Returns: number extracted as string. Ex: 70
"""
return discount_str.text.split('%')[0].replace('(','')
# using googlebot's user agent
headers = {
'User-Agent': 'Mozilla/5.0 AppleWebKit/27.0.1453 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Safari/27.0.1453'
}
res = requests.get('https://www.amazon.in/s?k=earphones', headers=headers)
soup = BeautifulSoup(res.content, 'html.parser')
for discount in soup.select('.a-letter-space+ span'):
# just remove extract_discount if you just want (70% off)
print(extract_discount(discount))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71806285
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号