
Umap & Matplotlib.Umap的新观点每次似乎都很糟糕。
我在Python中有一个没有监督的情感分析问题。我使用语句转换器库来获取tweet的嵌入(因为一些文本样本是直接从twitter中提取的),我还阅读了一些文章,表示降维很重要,而umap对此非常有用。
总体的问题是,当我想得到一个新的测试推特的新嵌入时,umap似乎给出了奇怪的坐标。我将遍历这些代码,这样任何读到这段代码的人都能理解。
- 创建了tweet列表。10正,10中性,10负。都变成了一个简单的数据格式.
- 采用全mpnet v2语句转换模型.代码:
model_st = SentenceTransformer('all-mpnet-base-v2')- 模型现在编码数据格式的tweet,现在我有768大小的嵌入。代码是:
umap_obj = umap.UMAP(n_neighbors=30, n_components=2, min_dist=0.0, metric='cosine', random_state=42).fit(embeddings)
umap_obj.embedding_由此得出的结果是:
array([[ 7.043991 , 10.03341 ],
[ 6.4562964, 9.504029 ],
[ 6.7481065, 11.092019 ],
[ 7.3372607, 11.114787 ],
[ 7.890366 , 10.493936 ],
[ 6.298611 , 10.29068 ],
[ 6.4775186, 9.898772 ],
[ 8.703255 , 9.839503 ],
[ 6.850452 , 10.553306 ],
[ 7.1775093, 10.757572 ],
[ 8.61553 , 8.281198 ],
[ 7.665401 , 8.742563 ],
[ 8.105979 , 8.283659 ],
[ 8.412901 , 8.686226 ],
[ 7.604193 , 8.318158 ],
[ 7.5261774, 9.969134 ],
[ 7.7710595, 9.204553 ],
[ 8.022583 , 9.164099 ],
[ 7.2784944, 8.836557 ],
[ 9.169669 , 9.772636 ],
[ 9.370931 , 10.3363 ],
[ 8.465871 , 10.676252 ],
[ 8.5332 , 11.112685 ],
[ 8.1095495, 11.277469 ],
[ 8.147169 , 10.263562 ],
[ 9.059501 , 11.015707 ],
[ 8.97215 , 10.662908 ],
[ 8.142927 , 9.835047 ],
[ 8.697013 , 10.231923 ],
[ 8.514813 , 9.202326 ]], dtype=float32)太好了!二维坐标。
- 我想为此使用一个简单的聚类算法,所以我使用了sklearn.cluster库中的k方法。代码:
amount_of_clusters = 3
k_means_model = KMeans(n_clusters=amount_of_clusters, random_state=1234)
k_means_model.fit(umap_obj.embedding_)
k_means_model.labels_我这样做是因为使用".labels_“行代码,我们会得到标签,这就是我在后面的代码行中将进行的聚类。所贴的标签如下:
array([0, 0, 0, 0, 2, 0, 0, 2, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 1], dtype=int32),
- ,我将新的2d坐标和标签k一起放入一个新的数据帧中。我发现很快就能把它们按标签正确地分开。代码:
k_means_df = pd.DataFrame(umap_obj.embedding_, columns=['x', 'y'])
k_means_df['labels'] = k_means_model.labels_
k_means_df并给出了结果:
x y labels
0 7.043991 10.033410 0
1 6.456296 9.504029 0
2 6.748106 11.092019 0
3 7.337261 11.114787 0
4 7.890366 10.493936 2
5 6.298611 10.290680 0
6 6.477519 9.898772 0
7 8.703255 9.839503 2
8 6.850452 10.553306 0
9 7.177509 10.757572 0
10 8.615530 8.281198 1
11 7.665401 8.742563 1
12 8.105979 8.283659 1
13 8.412901 8.686226 1
14 7.604193 8.318158 1
15 7.526177 9.969134 0
16 7.771060 9.204553 1
17 8.022583 9.164099 1
18 7.278494 8.836557 1
19 9.169669 9.772636 2
20 9.370931 10.336300 2
21 8.465871 10.676252 2
22 8.533200 11.112685 2
23 8.109550 11.277469 2
24 8.147169 10.263562 2
25 9.059501 11.015707 2
26 8.972150 10.662908 2
27 8.142927 9.835047 2
28 8.697013 10.231923 2
29 8.514813 9.202326 1- 现在在这个步骤。我分别得到标签0、1和2的所有坐标的列表。我为plt.scatter()函数创建了一个颜色列表,然后我只放置了一些简单的代码来显示情节。代码:
zero_x_points = k_means_df[k_means_df['labels'] == 0]['x'].tolist()
zero_y_points = k_means_df[k_means_df['labels'] == 0]['y'].tolist()
one_x_points = k_means_df[k_means_df['labels'] == 1]['x'].tolist()
one_y_points = k_means_df[k_means_df['labels'] == 1]['y'].tolist()
two_x_points = k_means_df[k_means_df['labels'] == 2]['x'].tolist()
two_y_points = k_means_df[k_means_df['labels'] == 2]['y'].tolist()
colors = ['#fc0505', '#0514fc', '#00920d']
fig, ax = plt.subplots(figsize=(20, 10))
plt.scatter(zero_x_points, zero_y_points, color=colors[0])
plt.scatter(one_x_points, one_y_points, color=colors[1])
plt.scatter(two_x_points, two_y_points, color=colors[2])
plt.colorbar()结果如下:
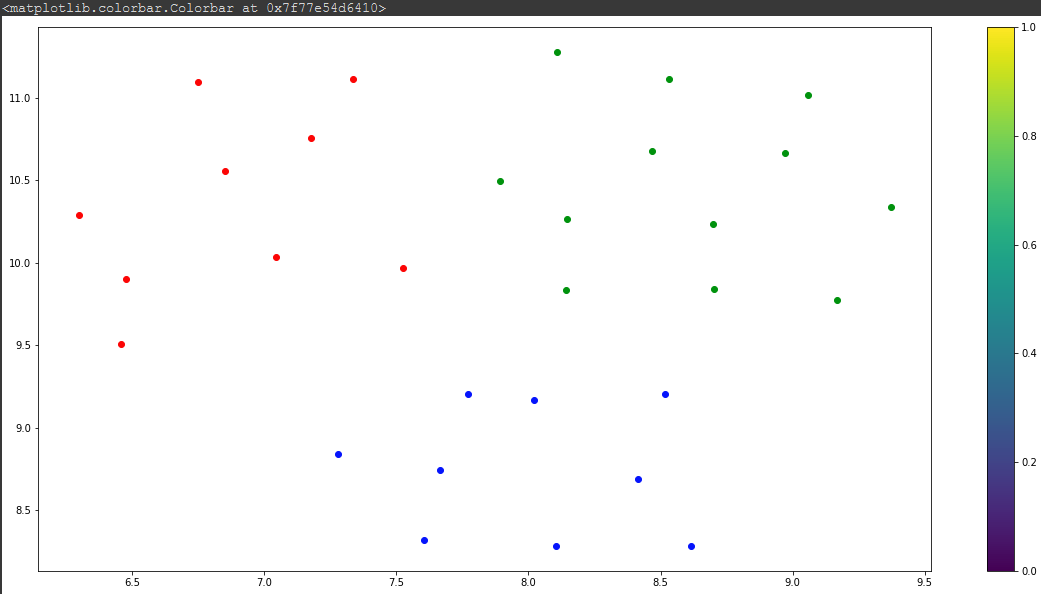
看上去不算太糟。现在来看真正的问题,那就是预测。
- KEY关于这个tweet测试的注意事项,我是在测试了一条简单的tweet之后才做的,这条推文是“很棒的游戏”(因此,您将看到的tweet被称为"dummy_test_two")。这个奇怪的结果已经发生在过去四天了。所以通过这条推文,它是从最初的推文列表(确切地说是积极的)中复制和粘贴的,所以我绝对确信这个结果是荒谬的,我肯定我做错了什么。代码:
# Make tweet.
dummy_tweet_two = "I'd like to slow down time so I can spend more hours on this. #CyberpunkGame"
# Encode it.
dummy_tweet_encoded_two = model_st.encode([dummy_tweet_two])
dummy_tweet_coords_two = umap_obj.transform(dummy_tweet_encoded_two)
print(f'Dummy tweet two coordindates: {dummy_tweet_coords_two}')由此得出的结果是:
Dummy tweet coords plane: [[ 7.748943 12.07401 ]]- 上面显示的结果(新的坐标为黑色):
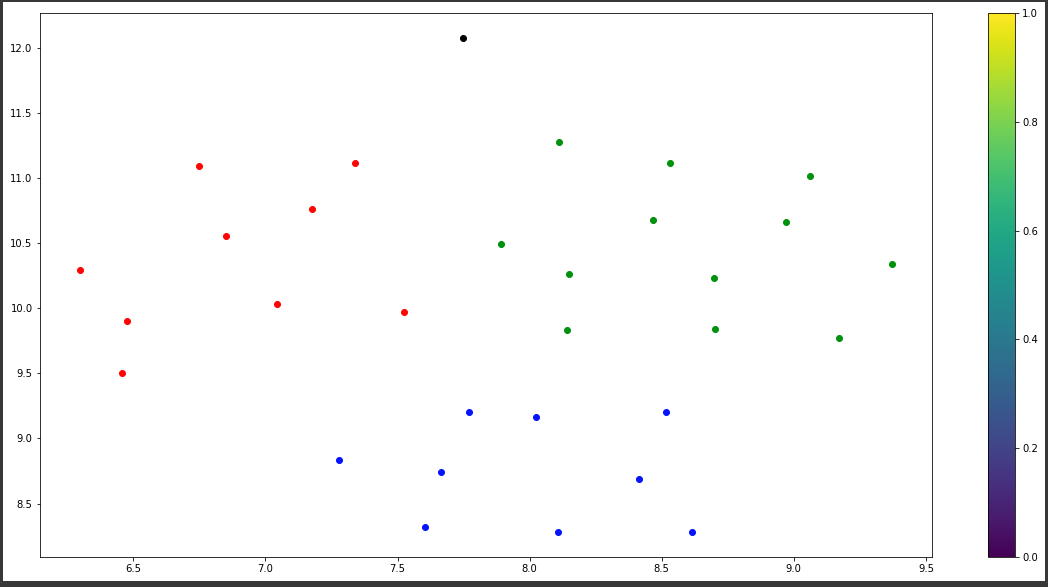
就是这个。这没有任何意义。正如我在dummy_tweet_two变量中所说的,这条推特在最初的积极推文列表中。它不可能从字面上的每一个群体中分离出来。
回答 1
Stack Overflow用户
发布于 2022-04-09 21:56:26
因此,proper之前的评论让我走上了正确的轨道,为什么我的旧实现没有产生正确的点结果。我得出的结论是,我没有用每个测试点调用umap对象上的fit函数。
首先,fit函数适合x嵌入空间。请参阅函数中的注释:https://umap-learn.readthedocs.io/en/latest/_modules/umap/umap_.html#UMAP.fit,这意味着我的常规点和测试点在技术上位于两个不同的空间。
代码示例,我指的是
# The tweet to use. This is already present in the list_of_tweets variable.
new_tweet = "Wonderful game, story was absolutely brilliant."
# Get the embedded version.
new_tweet_embedding = model_st.encode(new_tweet)
# Add the new embedding to the old.
new_embeddings = []
for embedding in embeddings:
new_embeddings.append(embedding)
new_embeddings.append(new_tweet_embedding)
print(f'Old tweet embedding (inside new list): {new_embeddings[0][:5]}\n\n')
print(f'New tweet embedding (inside new list): {new_embeddings[-1][:5]}')
# Create the new umap object that'll REALLY fit x into an embedded space.
new_umap_obj = umap.UMAP(n_neighbors=31, n_components=2, min_dist=0.0, metric='cosine', random_state=42).fit(new_embeddings)
new_umap_obj.embedding_记住了,变量"new_tweet“中的字符串值”精彩的游戏,故事绝对精彩“。是在我在最初的评论中显示的创建第一个2d情节的tweet的主列表中。所以我希望有一些类似的立场。
由于umap,主列表中的tweet具有以下坐标: x=10.252,y=19.692。
我测试的"new_tweet“变量有这些坐标,这要归功于umap: x=9.935,y=18.440
很明显非常相似,下面的图片显示他们很接近。我会把他们围起来让他们明白的。
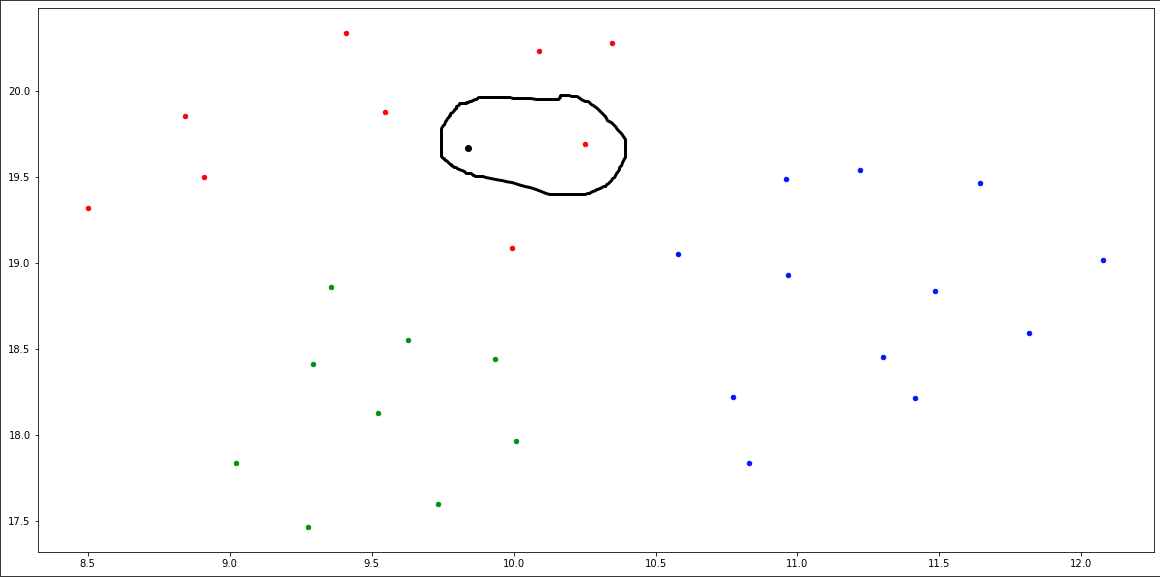
测试点是黑色的,原来的旁边是红色的。,就像保罗已经说过的,虽然,但由于不合适,它将不是精确的坐标,考虑到数据的大小,这是绝对可以理解的。
因此,这解决了我对为什么我的观点没有意义以及如何解决它的担忧。我在3条不同的推特上尝试了完全相同的过程,但没有一条是奇怪的。这些推文:
test_tweets = ["Great game, glad I managed to give it a shot. Good job to the devs.",
"A lot of room to upgrade I'd say, but this isn't really BAD.",
"A complete buggy and glitchy waste of time. Game even crashed during the loading screen once."]结果:
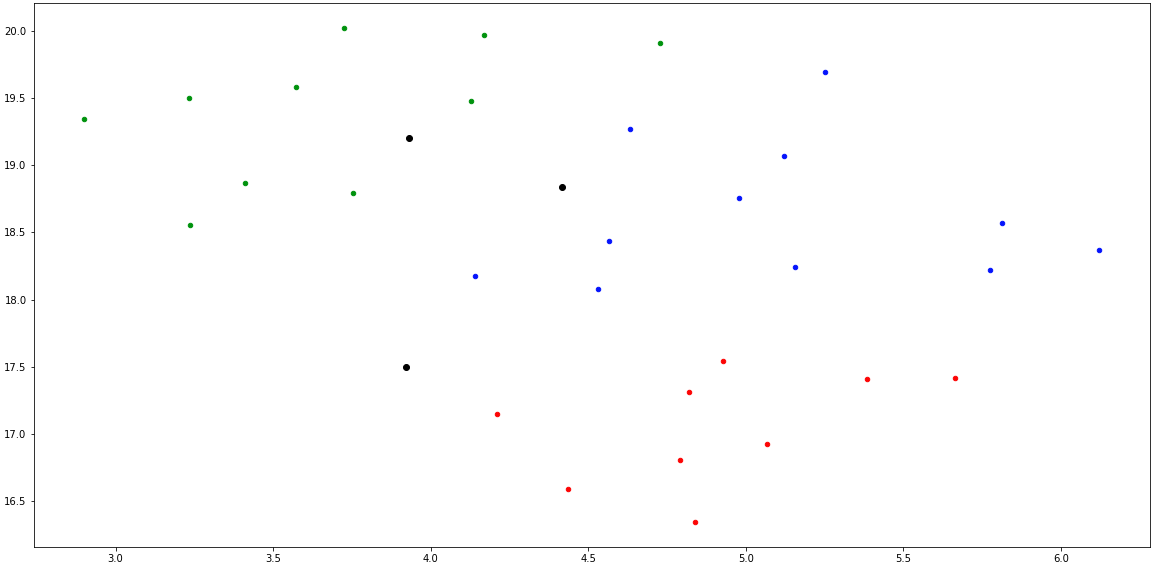
希望这能帮助任何有同样问题的人。
https://stackoverflow.com/questions/71745539
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号