
以小写(值为代码颜色)更改dict的值,以便在plotly.graph.object中接受为颜色参数
以小写(值为代码颜色)更改dict的值,以便在plotly.graph.object中接受为颜色参数
提问于 2022-03-30 17:30:00
因此,我试图从字典'Disaster_type‘中提取颜色,根据灾害的类型,在地线上绘制标记。
基本上,我想用它的颜色代码在图形中再现自然的弥散器。这是一种火山活动,把它涂成“橙色”。我想改变标记的大小,也取决于灾难的程度,但这还需要一天的时间。
以下是数据集的链接:https://www.kaggle.com/datasets/brsdincer/all-natural-disasters-19002021-eosdis
import plotly.graph_objects as go
import pandas as pd
import plotly as plt
df = pd.read_csv('1900_2021_DISASTERS - main.csv')
df.head()
df.tail()
disaster_set = {disaster for disaster in df['Disaster Type']}
disaster_type = {'Storm':'aliceblue',
'Volcanic activity':'orange',
'Flood':'royalblue',
'Mass movement (dry)':'darkorange',
'Landslide':'#C76114',
'Extreme temperature':'#FF0000',
'Animal accident':'gray55',
'Glacial lake outburst':'#7D9EC0',
'Earthquake':'#CD8C95',
'Insect infestation':'#EEE8AA',
'Wildfire':' #FFFF00',
'Fog':'#00E5EE',
'Drought':'#FFEFD5',
'Epidemic':'#00CD66 ',
'Impact':'#FF6347'}
# disaster_type_lower = {(k, v.lower()) for k, v in disaster_type.items()}
# print(disaster_type_lower)
# for values in disaster_type.values():
# disaster_type[values] = disaster_type.lowercase()
fig = go.Figure(data=go.Scattergeo(
lon = df['Longitude'],
lat = df['Latitude'],
text = df['Country'],
mode = 'markers',
marker_color = disaster_type_.values()
)
)
fig.show()我想不出是怎么回事,在我试着做那件事之后,我留下了评论。它改变了它们的小写,但我知道我不知道热得them...My大脑完全融化
回答 1
Stack Overflow用户
发布于 2022-03-30 18:26:52
- 这是熊猫图的一个简单案例
- 在kaggle上找到了与您的数据相同的数据,所以使用了
- 一种类型是未映射的极端温度,因此使用
fillna("red")消除任何错误。 - gray55给了我一个错误,因此将它替换为RGB等效。
import kaggle.cli
import sys
import pandas as pd
from zipfile import ZipFile
import urllib
import plotly.graph_objects as go
# fmt: off
# download data set
url = "https://www.kaggle.com/brsdincer/all-natural-disasters-19002021-eosdis"
sys.argv = [sys.argv[0]] + f"datasets download {urllib.parse.urlparse(url).path[1:]}".split(" ")
kaggle.cli.main()
zfile = ZipFile(f'{urllib.parse.urlparse(url).path.split("/")[-1]}.zip')
dfs = {f.filename: pd.read_csv(zfile.open(f)) for f in zfile.infolist()}
# fmt: on
df = dfs["DISASTERS/1970-2021_DISASTERS.xlsx - emdat data.csv"]
disaster_type = {
"Storm": "aliceblue",
"Volcanic activity": "orange",
"Flood": "royalblue",
"Mass movement (dry)": "darkorange",
"Landslide": "#C76114",
"Extreme temperature": "#FF0000",
"Animal accident": "#8c8c8c", # gray55
"Glacial lake outburst": "#7D9EC0",
"Earthquake": "#CD8C95",
"Insect infestation": "#EEE8AA",
"Wildfire": " #FFFF00",
"Fog": "#00E5EE",
"Drought": "#FFEFD5",
"Epidemic": "#00CD66 ",
"Impact": "#FF6347",
}
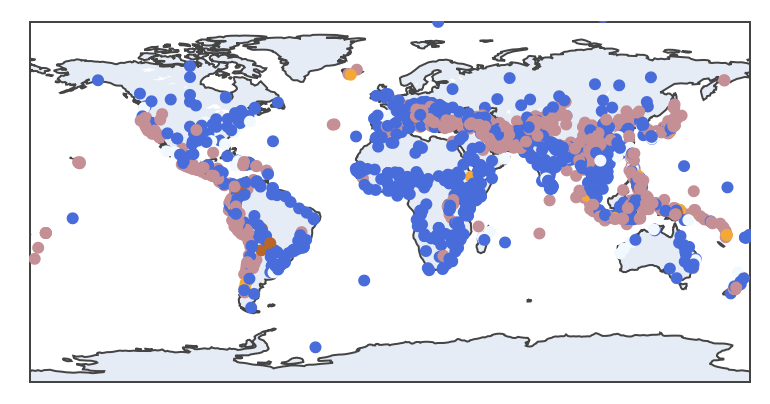
fig = go.Figure(
data=go.Scattergeo(
lon=df["Longitude"],
lat=df["Latitude"],
text=df["Country"],
mode="markers",
marker_color=df["Disaster Type"].map(disaster_type).fillna("red"),
)
)
fig.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71681652
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号