
非线性拟合回归
非线性拟合回归
提问于 2022-03-28 00:01:59
df <- data.frame(hour=c(5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23),
total=c(15507,132129,156909,81306,44413,51448,55308,63542,57564,54031,70319,53345,35137,15509,20134,5183,2554,20,203))
plot(df$hour, df$total)
fit1 <- lm(total~hour, data = df)
fit2 <- lm(total~poly(hour,2, raw = TRUE), data = df)
fit3 <- lm(total~poly(hour,3, raw = TRUE), data = df)
fit4 <- lm(total~poly(hour,4, raw = TRUE), data = df)
fit5 <- lm(total~poly(hour,5, raw = TRUE), data = df)
summary(fit1)$adj.r.squared
summary(fit2)$adj.r.squared
summary(fit3)$adj.r.squared
summary(fit4)$adj.r.squared
summary(fit5)$adj.r.squared如何确定数据最适合回归的方法?
如何计算临界点,全局最大值和局部最大值(如果有的话)。
尝试用调整后的r平方作为选择最佳曲线的依据,但我的临界点与曲线无关。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-28 00:16:21
“最佳匹配”是一个有多种答案的问题,取决于你的目标,但是:
AIC(fit1,fit2,fit3,fit4,fit5)
df AIC
fit1 3 450.4892
fit2 4 451.8506
fit3 5 453.3828
fit4 6 454.5851
fit5 7 446.4370表明fit5是最好的(最低的AIC)。bbmle::AICtab()提供了一个稍微有用的输出(也许)--只显示相对于最佳匹配的AIC,并根据匹配的优度对模型进行排序。
bbmle::AICtab(fit1,fit2,fit3,fit4,fit5)
dAIC df
fit5 0.0 7
fit1 4.1 3
fit2 5.4 4
fit3 6.9 5
fit4 8.1 6 如果你的模型是
beta0 + beta1*x + beta2*x^2 + beta3*x^3 ...那么一阶导数是
beta1 + 2*beta2*x + 3*beta3*x^2 + ...找到这个多项式的根应该给出临界点。
因此,例如。
pp <- polyroot(coef(fit5)[-1]*(1:5))应该给你fit5的关键点。
png("tmp.png")
par(las=1, bty="l")
plot(df$hour, df$total)
lines(df$hour, predict(fit5))
abline(v=Re(pp), col =2 )
dev.off()
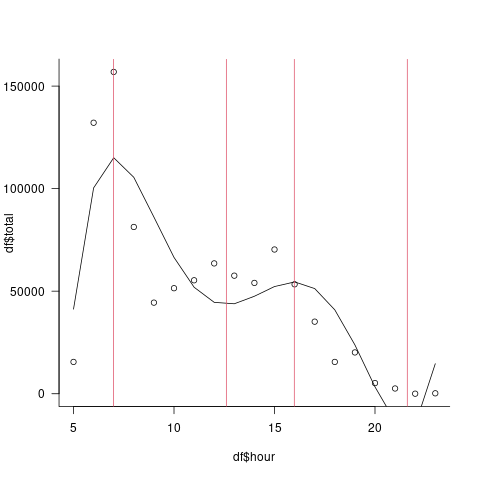
更多的实验表明,您还没有达到最佳的复杂性。使用AICc (“修正的”AIC,它说明了有限的样本大小):
bbmle::AICctab(fit5, fit7, fit10)
dAICc df
fit7 0.0 9
fit5 19.1 7
fit10 29.3 12也就是说,7号订单比5号订单或10号订单要好得多.
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71641204
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号