
如何用类别而不是数字来创建酒壶呢?
我刚开始在R,我正试图把我的头脑围绕着酒吧,为大学的任务。具体来说,我正在使用2018年通用社会调查数据集(代码本:https://www.thearda.com/Archive/Files/Codebooks/GSS2018_CB.asp),我试图弄清楚宗教对人们寻求心理健康帮助的方式是否有任何影响。我想用reliten (宗教性的自我评估-从强烈到没有宗教)作为IV和tlkclrgy (询问一个有心理健康问题的人是否应该接触宗教领袖--是或不是)作为DV。为了更好地可视化数据,我想在x轴上创建一个与reliten并排的条形图,看看有多少人在tlkclrgy上回答是和否。我的问题是,在酒吧里,我得到的是数字,而不是类别(从强烈到没有宗教信仰)。这是我试过的,但我一直在x轴上得到NA:
GSS$reliten <- factor(as.character(GSS$reliten),
levels = c("No religion", "Somewhat
strong", "Not very strong",
"Strong"))
GSS <- GSS18[!GSS18$tlkclrgy %in% c(0, 8, 9),]
GSS$reliten <- as_factor(GSS$reliten)
GSS$tlkclrgy <- as_factor(GSS$tlkclrgy)
ggplot(data=GSS,mapping=aes(x=reliten,fill=tlkclrgy))+
geom_bar(position="dodge")有人有什么建议吗?
回答 1
Stack Overflow用户
发布于 2022-03-23 17:38:41
这里有完整的代码下载码本和数据,表的两列感兴趣和绘制频率。
1.读取数据
数据将被下载到一个临时目录中,以保持磁盘的适口性。使用前两条指令是可选的。
od <- getwd()
setwd("~/Temp")这些链接指向需要读取的两个文件和文件名。
cols_url <- "https://osf.io/ydxu4/download"
cols_file <- "General Social Survey, 2018.col"
data_url <- "https://osf.io/e76rv/download"
data_file <- "General Social Survey, 2018.dat"
download.file(cols_url, cols_file, mode = "wb")
download.file(data_url, data_file, mode = "wb")现在阅读代码本并对其进行处理,提取列宽和列名。
cols <- readLines(cols_file)
cols <- strsplit(cols, ": ")
widths_char <- sapply(cols, '[', 2)
i_widths <- grepl("-", widths_char)
f <- function(x) -eval(parse(text = x)) + 1L
widths <- rep(1L, length(widths_char))
widths[i_widths] <- f(widths[i_widths])
col_names <- sapply(cols, '[', 1)
col_names <- trimws(sub("^.[^ ]* ", "", col_names))
col_names <- tolower(col_names)最后,读取固定宽度的文本文件。
df1 <- read.fwf(data_file, widths = widths, header = FALSE, na.strings = "-", col.names = col_names)2.数据表
找出我们希望使用grep的两列在哪里。
i_cols <- c(
grep("reliten", col_names, ignore.case = TRUE),
grep("tlkclrgy", col_names, ignore.case = TRUE)
)
head(df1[i_cols])列出这些列并强制使用data.frame。然后强迫列考虑因素。
这里有一个问题,在公布的调查中,tlkclrgy 没有答案3,但是数据文件中有答案3,所以我创建了一个额外的因子级别。
GSS <- as.data.frame(table(df1[i_cols]))
labels_reliten <- c(
"Not applicable",
"Strong",
"Not very strong",
"Somewhat Strong",
"No religion",
"Don't know",
"No answer"
)
levels_reliten <- c(0, 1, 2, 3, 4, 8, 9)
labels_tlkclrgy <- c(
"Not applicable",
"Yes",
"No",
"Not in codebook",
"Don't know",
"No answer"
)
levels_tlkclrgy <- c(0, 1, 2, 3, 8, 9)
GSS$reliten <- factor(
GSS$reliten,
labels = labels_reliten,
levels = levels_reliten
)
GSS$tlkclrgy <- factor(
GSS$tlkclrgy,
labels = labels_tlkclrgy,
levels = levels_tlkclrgy
)3.绘制频率表
library(ggplot2)
ggplot(data = GSS, mapping = aes(x = reliten, y = Freq, fill = tlkclrgy)) +
geom_col(position = "dodge")
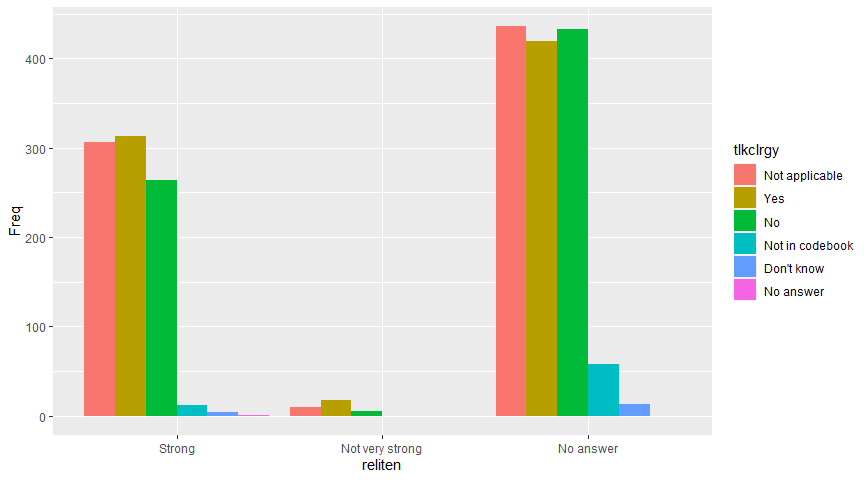
https://stackoverflow.com/questions/71590399
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号