
Python:当从pdf中提取文本时,如何解决合并的单词?
我正在努力从一组pdf文件中提取单词。这些文件是我从网上下载的学术论文。
这些数据存储在我的本地设备中,按照名称排序,在项目文件夹中遵循这个相对路径:'./papers/ data‘。您可以找到我的数据这里。
我的代码正在项目回购('./ code ')的代码文件夹中执行。
代码的pdf单词提取部分如下所示:
import PyPDF2 as pdf
from os import listdir
#Open the files:
#I) List of files:
files_in_dir = listdir('../papers/data')
#II) Open and saving files to python objects:
papers_text_list = []
for idx in range(len(files_in_dir)):
with open(f"../papers/data/{files_in_dir[idx]}", mode="rb") as paper:
my_pdf = pdf.PdfFileReader(paper)
vars()["text_%s" % idx] = ''
for i in range(my_pdf.numPages):
page_to_print = my_pdf.getPage(i)
vars()["text_%s" % idx] += page_to_print.extractText()
papers_text_list.append(vars()["text_%s" %idx])问题是,对于某些文本,我会在python列表中合并单词。
text_1.split().‘、’'erentoutdoorenvironmentsinkindergartenchildren',‘、’™™水平‘、’年龄3‘、’Œ5.‘、'ndingsrevealedthatchildren’、‘’、sPAlevel sPAlevel‘’、'naturalgreenenvironmentsthaninthekindergarten','™soutdoorenvir-‘、’环境‘表示绿色环境、’更好的机会‘、’更好的机会‘、’有利于儿童‘、.
而其他列表是以正确的方式导入的。
text_0.split()“城市”、“林业”、“城市”、“绿化”、“16”、“2016年”、“76-83内容”、“列表”、“可用”、“at”、“科学指导”、“城市”、“林业”、“&”、“城市”、“绿化”、.
此时,我认为令牌化可以解决我的问题。因此,我给它一个机会,nltk模块。
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
doc = tokenizer,tokenize(text_1)
paper_words = [token for token in doc]
paper_words_lower = []
for token in paper_words:
try:
word = token.lower()
except TypeError:
word = token
finally:
paper_words_lower.append(word)“‘contentslistsavailableat”、“sciencedirecturbanforestry”、“urbangreening”、“journalhomepage”、“www”、“elsevier”、“com”、“locate”、“ufug”、“ufug elsevier”、“turkey”、“sectionalstudyofassociationswith”、“turkey”、“物理活动”、“screentime”、“generalhealth”、“andover重量”、“abdullahakpinar”、“adnanmenderesüniversitesi”、“ziraatfakültesi”、“peyzajmimarl”、“bülüm”、“100 com”、“土耳其.‘一般健康’,‘独生子女’,'sagewas',‘与他们的体重有关’,……
我甚至试过用spacy模块..。但问题仍然存在。
我在这里的结论是,如果问题能够解决,就必须在pdf提取单词部分。我发现了这个与StackOverflow相关的问题,但是这个解决方案不能解决我的问题。
为什么会发生这种情况?我该怎么解决呢?
PD:作为麻烦的例子的列表上的一篇文章是"AKPINAR_2017_Urban green spaces for children.pdf"。
您可以使用以下代码导入。
import PyPDF2 as pdf
with open("AKPINAR_2017_Urban green spaces for children.pdf", mode="rb") as paper:
my_pdf = pdf.PdfFileReader(paper)
text = ''
for i in range(my_pdf.numPages):
page_to_print = my_pdf.getPage(i)
text += page_to_print.extractText()回答 3
Stack Overflow用户
发布于 2022-03-19 20:13:44
到目前为止,最简单的方法是使用现代PDF查看器/编辑器,允许剪切和粘贴,并进行一些额外的调整。我没有问题,大声阅读或提取这些学术期刊,因为它们是(除一)可读性的文本,从而输出良好的纯文本。--总共花了4秒的时间把24个PDF文件(除了#24of25之外,每秒6个)输出到可读的文本中。使用forfiles /m *.pdf /C "cmd /c pdftotext -simple2 @file @fname.txt"。将结果与第一个不可读示例进行比较。
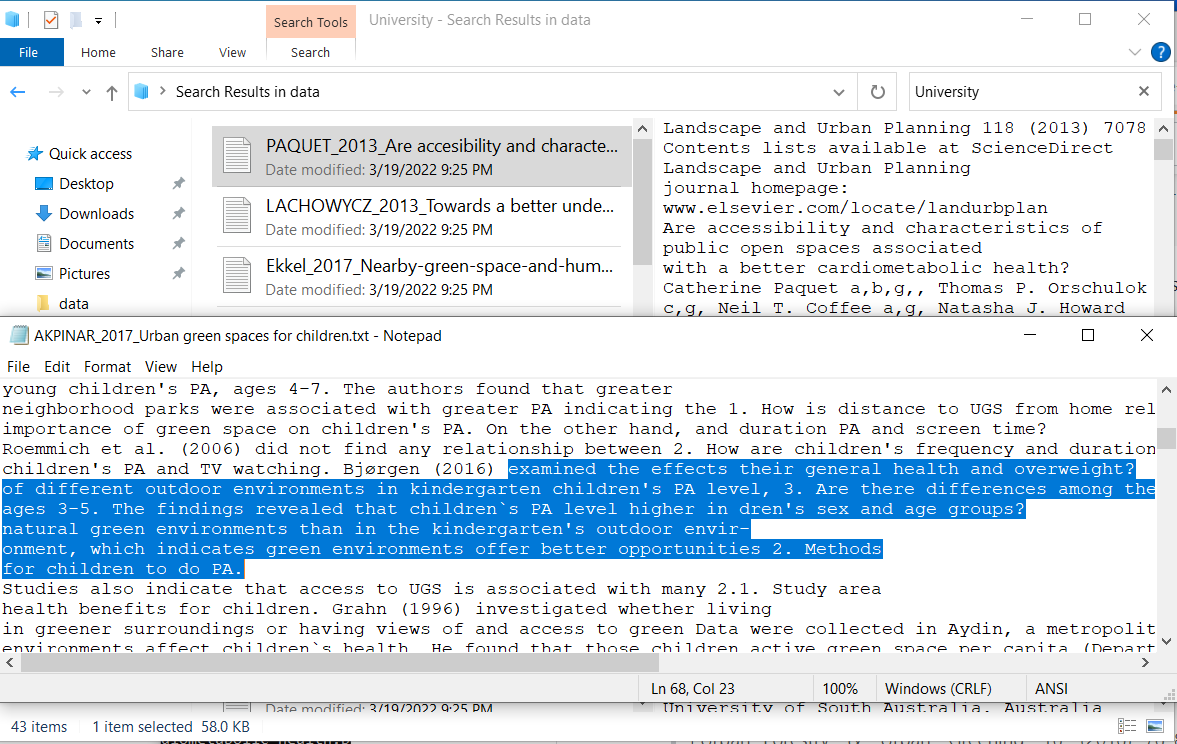
但是,有一个例外是Hernadez_2005,因为它是图像,因此需要进行OCR转换,并对编辑器进行大量(并非微不足道)的训练,以处理科学术语和外国连字符,以及不断变化的风格。但是,如果在WordPad中做一些工作,可以产生足够好的结果,适合在Microsoft中进行编辑,您可以将其保存为纯文本,以便在Python中进行解析。

Stack Overflow用户
发布于 2022-03-16 21:04:34
是的,这是提取的一个问题。您提到的两个示例文档中的空格是不同的:


PDF通常并不总是有一个清晰的线条和词的概念。它们在文档中的某些地方放置字符/文本框。抽取不能像txt文件那样读"char by char“,它会从左上角到右下角解析它,并使用距离来假设什么是一行,什么是单词等等。因为第一张图片中的字符似乎不仅使用空格字符,而且还使用左右字符边距来为文本创建更好的间距,所以解析者很难理解它。
每个解析者都会这样做,所以尝试一些不同的解析器可能是有意义的,也许另一个解析器是针对具有类似模式的文档进行培训/设计的,并且能够正确地解析它。另外,由于示例中的PDF确实有所有有效的空格,但随后通过某些负值内容将字符更接近于彼此,从而混淆了解析器,所以正常复制和粘贴到txt文件不会出现这个问题,因为它会忽略页边距内容。
如果我们谈论的是大量的数据,并且您愿意花更多的时间在这上面,您可以查看光学字符识别后校正(OCR后校正)上的一些源,它们是试图修复分析错误的文本的模型(尽管它通常更多地关注通过不同字体等错误识别的字符的问题,而不是间距问题)。
Stack Overflow用户
发布于 2022-03-19 02:16:04
PyPDF2自2018年以来就一直没有维护。
问题在于,有很多网页推荐PyPDF2通过网络,但实际上现在没有人使用它。
我最近也这么做,直到意识到PyPDF2已经死了。最后我使用了https://github.com/jsvine/pdfplumber。智能交通系统维护积极,操作简单,运行良好。
https://stackoverflow.com/questions/71503225
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号