
根据Google的结果创建CSV
根据Google的结果创建CSV
提问于 2022-03-11 20:02:05
我正在使用Wikidata查询服务来获取值,这是代码:
pip install sparqlwrapper
import sys
from SPARQLWrapper import SPARQLWrapper, JSON
endpoint_url = "https://query.wikidata.org/sparql"
query = """#List of organizations
SELECT ?org ?orgLabel
WHERE
{
?org wdt:P31 wd:Q4830453. #instance of organizations
?org wdt:P17 wd:Q96. #Mexico country
SERVICE wikibase:label { bd:serviceParam wikibase:language "en"}
}"""
def get_results(endpoint_url, query):
user_agent = "WDQS-example Python/%s.%s" % (sys.version_info[0], sys.version_info[1])
# TODO adjust user agent; see https://w.wiki/CX6
sparql = SPARQLWrapper(endpoint_url, agent=user_agent)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
return sparql.query().convert()
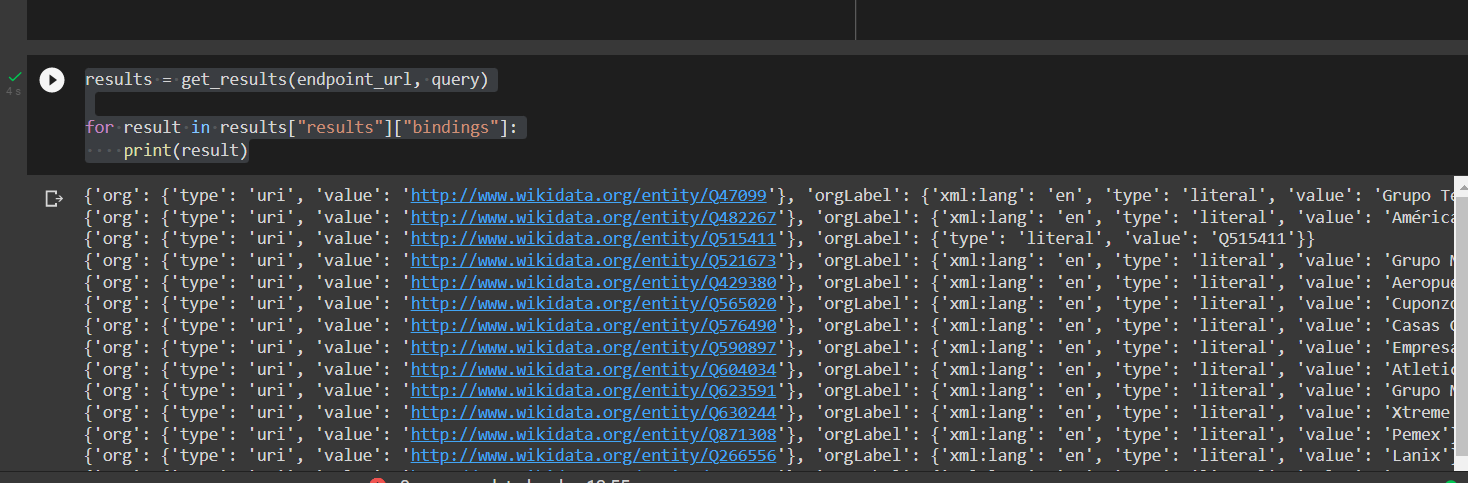
results = get_results(endpoint_url, query)
for result in results["results"]["bindings"]:
print(result)这段代码给出了我需要的数据,但是我在试图用这一行获取这些信息时遇到了问题:
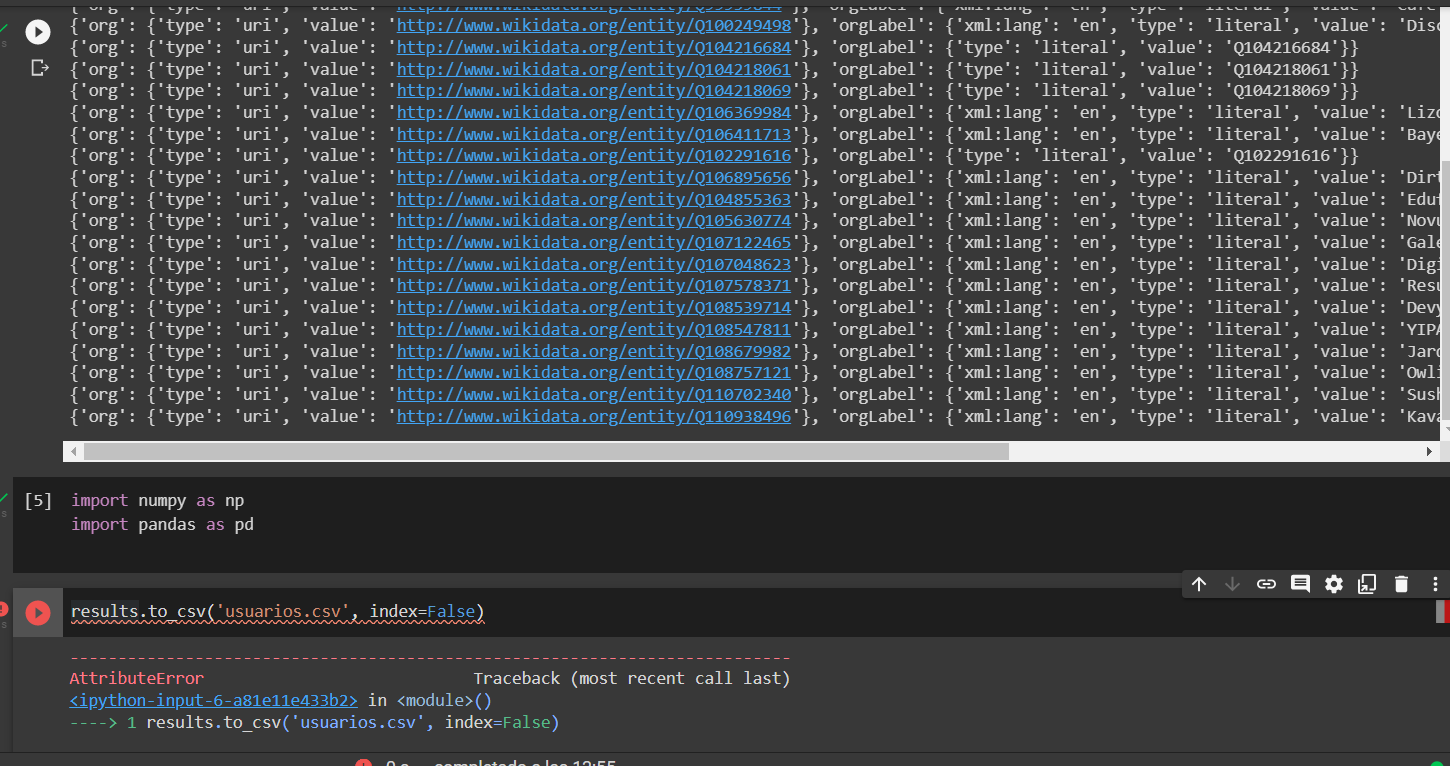
results.to_csv('results.csv', index=False)有了这个错误:
'dict' object has no attribute 'to_csv'我进口熊猫和numpy来做它,但我仍然有问题,所以我想知道如何把这个结果以一种格式,以创建我的csv文件的数据。
这里有一些截图。
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-03-12 14:23:09
results是一个字典,它是一个不能调用方法to_csv的python数据结构。
为了从python字典中安全地存储csv,可以使用外部库(也请参阅文档 on python.org)。
具体的解决方案取决于具体要导出的(元)数据。在下面的文章中,我假设您希望为org和orgLabel存储org和orgLabel。
import csv
bindings = results['results']['bindings']
sparqlVars = ['org', 'orgLabel']
metaAttribute = 'value'
with open('results.csv', 'w', newline='') as csvfile :
writer = csv.DictWriter(csvfile, fieldnames=sparqlVars)
writer.writeheader()
for b in bindings :
writer.writerow({var:b[var][metaAttribute] for var in sparqlVars})产出如下:
org,orgLabel
http://www.wikidata.org/entity/Q47099,"Grupo Televisa, owner of TelevisaUnivision"
http://www.wikidata.org/entity/Q429380,Aeropuertos y Servicios Auxiliares
http://www.wikidata.org/entity/Q482267,América Móvil
...Stack Overflow用户
发布于 2022-03-20 16:41:34
作为https://github.com/WolfgangFahl/pyLoDStorage的提交人
我要指出的是,pyLodStorage的SPARQL类显式地使转换到其他格式变得简单。
pip install pyLodStoragesparqlquery --query 'SELECT ?org ?orgLabel
WHERE
{
?org wdt:P31 wd:Q4830453. #instance of organizations
?org wdt:P17 wd:Q96. #Mexico country
SERVICE wikibase:label { bd:serviceParam wikibase:language "en"}
}' --format csv结果:
"org","orgLabel"
"http://www.wikidata.org/entity/Q47099","Grupo Televisa, owner of TelevisaUnivision"
"http://www.wikidata.org/entity/Q482267","América Móvil"
"http://www.wikidata.org/entity/Q515411","Q515411"
"http://www.wikidata.org/entity/Q521673","Grupo Modelo"当然,您可以通过python直接获得相同的结果:
from lodstorage.sparql import SPARQL
from lodstorage.csv import CSV
sparqlQuery="""SELECT ?org ?orgLabel
WHERE
{
?org wdt:P31 wd:Q4830453. #instance of organizations
?org wdt:P17 wd:Q96. #Mexico country
SERVICE wikibase:label { bd:serviceParam wikibase:language "en"}
}"""
sparql=SPARQL("https://query.wikidata.org/sparql")
qlod=sparql.queryAsListOfDicts(sparqlQuery)
csv=CSV.toCSV(qlod)
print(csv)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71444069
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号