
为什么Parallel.For不能快速处理堆密集型操作?
对于某些操作,Parallel可以很好地按照CPU的数量进行扩展,但对于其他操作,它却没有。
考虑下面的代码,function1得到10倍的改进,而function2得到3倍的改进。这是由于内存分配,还是GC?
void function1(int v) {
for (int i = 0; i < 100000000; i++) {
var q = Math.Sqrt(v);
}
}
void function2(int v) {
Dictionary<int, int> dict = new Dictionary<int, int>();
for (int i = 0; i < 10000000; i++) {
dict.Add(i, v);
}
}
var sw = new System.Diagnostics.Stopwatch();
var iterations = 100;
sw.Restart();
for (int v = 0; v < iterations; v++) function1(v);
sw.Stop();
Console.WriteLine("function1 no parallel: " + sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms"));
sw.Restart();
Parallel.For(0, iterations, function1);
sw.Stop();
Console.WriteLine("function1 with parallel: " + sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms"));
sw.Restart();
for (int v = 0; v < iterations; v++) function2(v);
sw.Stop();
Console.WriteLine("function2 no parallel: " + sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms"));
sw.Restart();
Parallel.For(0, iterations, function2);
sw.Stop();
Console.WriteLine("function2 parallel: " + sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms"));我机器上的输出:
function1 no parallel: 2 059,4 ms
function1 with parallel: 213,7 ms
function2 no parallel: 14 192,8 ms
function2 parallel: 4 491,1 ms环境:
Win 11,.Net 6.0,发布版本
i9第12代,16核,24 DDR5,32 GB DDR5
经过更多的测试后,内存分配似乎不能很好地扩展到多个线程。例如,如果我将函数2改为:
void function2(int v) {
Dictionary<int, int> dict = new Dictionary<int, int>(10000000);
}结果是:
function2 no parallell: 124,0 ms
function2 parallell: 402,4 ms内存分配不能很好地扩展到多线程的结论吗?
回答 3
Stack Overflow用户
发布于 2022-03-12 11:00:00
tl;dr:堆分配争用。
您的第一个函数是令人尴尬的平行。每个线程都可以在与其他线程很少交互的情况下进行计算。因此,它可以很好地扩展到多个线程。正确地指出,您的第一次计算使用的是非共享的、每个线程的处理器寄存器。
您的第二个函数,当它分配字典时,不那么令人尴尬的平行。每个线程的计算是独立于其他线程的,除了它们使用您机器的RAM子系统之外。因此,您可以在硬件级别看到一些线程到线程的争用,因为线程级的缓存数据被写入并从机器级RAM中读取。
您的第二个不预先分配内存的函数不是令人尴尬的并行功能。为什么不行?每个.Add()操作都必须在共享堆中分配一些数据。这不能并行完成,因为所有线程共享同一个堆。相反,它们必须是同步的。dotnet库尽可能好地并行化堆操作,但在线程A分配堆数据时,它们至少不能避免对线程B的某些阻塞。所以这些线会让彼此慢下来。
单独的进程而不是单独的线程是一种扩展工作负载的好方法,比如您的非预分配的第二个函数。每个进程都有自己的堆。
Stack Overflow用户
发布于 2022-03-11 11:42:17
第一个功能在寄存器中工作。更多核心=更多寄存器。
第二个功能是关于记忆的。更多的核心=只有更多的L1缓存,但共享内存。一千万个元素数据集当然只来自内存,因为即使是L3也不够大。这假设jit语言会将分配优化为重用缓冲区。如果没有,那么也存在分配开销。因此,您应该在每次新的迭代中重用字典,而不是重新创建。
此外,您还使用增量整数索引保存数据。简单的数组可以在这里工作,当然,在迭代之间可以重用。它应该比字典具有更少的内存占用。
Stack Overflow用户
发布于 2022-03-12 20:11:29
并行编程并不是那么简单。使用Parallel.For()或Parallel.ForEach()不会自动使程序并行。并行编程并不是要调用任何高级函数(在任何编程语言中)来使代码并行。是准备你的代码成为并行的。
实际上,您根本没有任何类似的东西,也没有func1或func2。作为基础,并行的两种基本类型是:
按任务,将复杂的任务拆分为较小的子任务,每个子任务将同时处理不同的核心、CPU或节点(在计算机集群中)。
通过数据,将一个大数据集分割成几个较小的片,每个片将同时处理不同的核心、CPUs或节点。
数据并行化要实现的难度要大得多,而且并不总是提供真正的性能增益。
Func1并不是真正的并行,它只是一个繁重的计算,同时运行。(您的CPU只是在争论谁将首先完成100 m for循环)使用Parallel.For(),您只是在线程中生成这个重函数100次。包含Task.Run()的单个for循环的结果几乎相同
如果您只在一个线程/核心中运行这个线程/核心,那么显然需要一些时间。如果你在所有的核心运行将会更快。这里没有什么大错误,虽然是一个并发代码,但实际上并不是并行的。此外,调用这些任务100次,如果没有这些CPU核(或集群中的节点),那么并行/并发代码将受到机器中实际CPU核的限制(在以后的示例中将看到)
现在是关于Func2和与内存堆的交互。是的,每种带有内置GC的现代语言都很昂贵。在一个复杂的算法中,最昂贵的操作之一是垃圾收集,有时它可以代表90%以上的CPU时间。
让我们分析一下您的function2
- 将新字典声明为函数范围
- 用100百万项填充本字典
- 在作用域外,您在Parallel.For中调用了包含100个交互的Parallel.For。
- 100个不同的作用域用100个数据填充100个不同的字典
- 这些作用域之间没有任何交互
如前所述,这不是并行编程,而是并发编程。在每个作用域中有100块数据块,它们之间没有相互作用
但还有第二个因素。您的function2操作是一个写操作(它意味着向集合添加-向上-删除某些内容)。嗯,如果只是一堆随机数据,你可以承认一些损失和不一致,好吧。但是,如果你正在处理真实的数据,并且不能允许任何形式的损失或不一致,那么坏消息。写入相同的内存地址(对象引用)没有真正的并行。您将需要一个同步contex,这将使事情变得更慢,并且这些同步操作总是并发的,因为如果一个线程正在写入内存引用,则另一个线程必须等到其他线程离开。实际上,使用多个线程来编写数据可能会使代码更慢而不是更快,特别是在并行操作不受CPU限制的情况下。
为了获得数据并行的实际收益,您必须对这些分区数据使用大量计算uppon。
让我们检查下面的代码,根据您的方法,但进行一些更改:
var rand = new Random();
var operationSamples = 256;
var datasetSize = 100_000_000;
var computationDelay = 50;
var cpuCores = Environment.ProcessorCount;
Dictionary<int, int> datasetWithLoss = new(datasetSize);
Dictionary<int, int> dataset = new(datasetSize);
double result = 0;
Stopwatch sw = new();
ThreadPool.SetMinThreads(1, 1);
int HeavyComputation(int delay)
{
int iterations = 0;
var end = DateTime.Now + TimeSpan.FromMilliseconds(delay);
while (DateTime.Now < end)
iterations++;
return iterations;
}
double SequentialMeanHeavyComputation(int maxMilliseconds, int samples = 64)
{
double sum = 0;
for (int i = 0; i < samples; i++)
sum += HeavyComputation(maxMilliseconds);
return sum / samples;
}
double ParallelMeanHeavyComputation(int maxSecondsCount, int samples = 64, int threads = 4)
{
ThreadPool.SetMaxThreads(threads, threads);
ThreadPool.GetAvailableThreads(out int workerThreads, out _);
Console.WriteLine($"Available Threads: {workerThreads}");
var _lockKey = new object();
double sum = 0;
int offset = samples / threads;
List<Action> tasks = new();
for (int i = 0; i < samples; i++)
tasks.Add(new Action(() =>
{
var result = HeavyComputation(maxSecondsCount);
lock (_lockKey)
sum += result;
}));
Parallel.Invoke(new ParallelOptions { MaxDegreeOfParallelism = threads }, tasks.ToArray());
return sum / samples;
}
void SequentialDatasetPopulation(int size)
{
for (int i = 0; i < datasetSize; i++)
dataset.TryAdd(i, Guid.NewGuid().GetHashCode());
}
void ParalellDatasetPopulation(int size, int threads)
{
var _lock = new object();
ThreadPool.SetMaxThreads(threads, threads);
ThreadPool.GetAvailableThreads(out int workerThreads, out _);
Console.WriteLine($"Available Threads: {workerThreads}");
Parallel.For(0, datasetSize, new ParallelOptions { MaxDegreeOfParallelism = threads }, (i) =>
{
var value = Guid.NewGuid().GetHashCode();
lock (_lock)
dataset.Add(i, value);
});
}
double SequentialReadOnlyDataset()
{
foreach (var x in dataset)
{
HeavyComputation((int)Math.Tan(Math.Cbrt(Math.Log(Math.Log(x.Value)))) / 10);
}
return 0;
}
double ParallelReadOnlyDataset()
{
Parallel.ForEach(dataset, x =>
{
HeavyComputation((int)Math.Tan(Math.Cbrt(Math.Log(Math.Log(x.Value)))) / 10);
});
return 0;
}
void ParalellDatasetWithLoss(int size, int threads)
{
ThreadPool.SetMaxThreads(threads, threads);
ThreadPool.GetAvailableThreads(out int workerThreads, out _);
Console.WriteLine($"Available Threads: {workerThreads}");
Parallel.For(0, datasetSize, new ParallelOptions { MaxDegreeOfParallelism = threads }, (i) =>
{
int value = Guid.NewGuid().GetHashCode();
datasetWithLoss.Add(i, value);
});
}
sw.Restart();
result = SequentialMeanHeavyComputation(computationDelay, operationSamples);
sw.Stop();
Console.WriteLine($"{nameof(SequentialMeanHeavyComputation)} sequential tasks: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
result = ParallelMeanHeavyComputation(computationDelay, operationSamples, threads: cpuCores);
sw.Stop();
Console.WriteLine($"{nameof(ParallelMeanHeavyComputation)} parallel tasks (CPU threads match count): {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
result = ParallelMeanHeavyComputation(computationDelay, operationSamples, threads: 100);
sw.Stop();
Console.WriteLine($"{nameof(ParallelMeanHeavyComputation)} parallel tasks (Higher thread count): {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
result = ParallelMeanHeavyComputation(computationDelay, operationSamples, threads: 4);
sw.Stop();
Console.WriteLine($"{nameof(ParallelMeanHeavyComputation)} parallel tasks (Lower thread count): {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
SequentialDatasetPopulation(datasetSize);
sw.Stop();
Console.WriteLine($"{nameof(SequentialDatasetPopulation)} sequential data population: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
dataset.Clear();
sw.Restart();
ParalellDatasetPopulation(datasetSize, cpuCores);
sw.Stop();
Console.WriteLine($"{nameof(ParalellDatasetPopulation)} parallel data population: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
ParalellDatasetWithLoss(datasetSize, cpuCores);
sw.Stop();
Console.WriteLine($"{nameof(ParalellDatasetWithLoss)} parallel data with loss: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
Console.WriteLine($"Lossless dataset count: {dataset.Count}");
Console.WriteLine($"Dataset with loss: {datasetWithLoss.Count}\n");
datasetWithLoss.Clear();
sw.Restart();
SequentialReadOnlyDataset();
sw.Stop();
Console.WriteLine($"{nameof(SequentialReadOnlyDataset)} sequential reading operations: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
sw.Restart();
ParallelReadOnlyDataset();
sw.Stop();
Console.WriteLine($"{nameof(ParallelReadOnlyDataset)} parallel reading operations: {sw.Elapsed.TotalMilliseconds.ToString("### ##0.0ms\n")}");
Console.Read();输出:
SequentialMeanHeavyComputation sequential tasks: 12 800,7ms
Available Threads: 15
ParallelMeanHeavyComputation parallel tasks (CPU threads match count): 860,3ms
Available Threads: 99
ParallelMeanHeavyComputation parallel tasks (Higher thread count): 805,0ms
Available Threads: 3
ParallelMeanHeavyComputation parallel tasks (Lower thread count): 3 200,4ms
SequentialDatasetPopulation sequential data population: 9 072,4ms
Available Threads: 15
ParalellDatasetPopulation parallel data population: 23 420,0ms
Available Threads: 15
ParalellDatasetWithLoss parallel data with loss: 6 788,3ms
Lossless dataset count: 100000000
Dataset with loss: 77057456
SequentialReadOnlyDataset sequential reading operations: 20 371,0ms
ParallelReadOnlyDataset parallel reading operations: 3 020,6ms
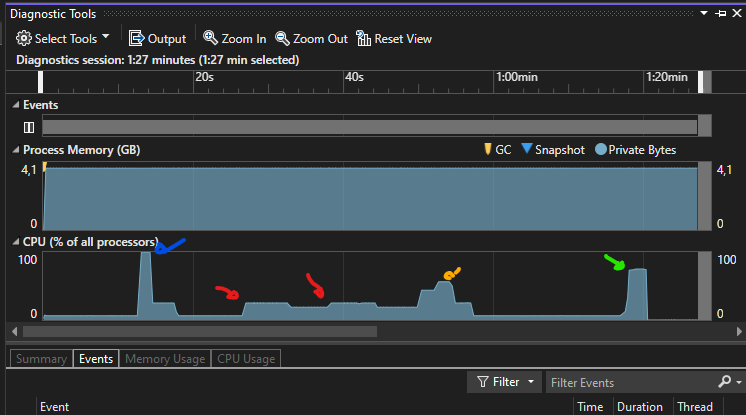
(红色: 25%,橙色: 56%,绿色: 75%,蓝色: 100%)
使用任务并行性,我们使用100%的CPU线程实现了超过20倍的性能。(在本例中,并不总是这样)
在只读数据并行中,通过一些计算,我们的CPU使用率提高了近6,5倍-- 56% (计算越少,差异就越短)。
但是,试图实现数据的“真正的并行性”来编写我们的性能要慢两倍多,而且CPU不能仅仅使用25%的综合上下文就可以使用全部的潜力。
使用Conclusions:的Parallel.For不能保证您的代码真的并行运行,也不能保证运行得更快。它需要以前的代码/数据准备和深入分析、基准和调优。
还请检查此Microsoft文档,其中讨论了并行代码中的坏蛋。
https://stackoverflow.com/questions/71434976
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号