
在Spark中显示在Hive表上创建表--将CHAR、VARCHAR视为字符串
我需要以编程的方式为Hive表和视图生成DDL语句。我试着用Spark和Beeline来完成这个任务。每条语句的直线时间大约为5-10秒,而斯派克在几毫秒内完成了同样的工作。我计划使用火花,因为它比直线更快。使用spark从hive获取DDL语句的一个缺点是,它将CHAR、VARCHAR字符视为字符串,并且不保留CHAR、VARCHAR数据类型的长度信息。同时直线保存CHAR、VARCHAR数据类型的数据类型和长度信息。我正在使用星火2.4.1和Beeline 2.1.1。
给出下面的示例create命令及其显示create输出。
直线输出:
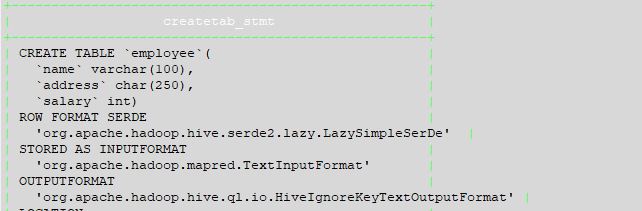
火花-壳牌:
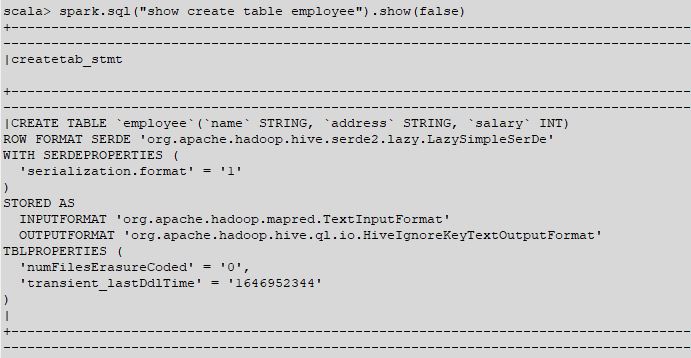
我想知道在Spark端是否有任何配置来保留CHAR、VARCHAR数据类型的数据类型和长度信息。如果有其他方法可以快速从蜂巢获得DDL,我也会同意的。
回答 1
Stack Overflow用户
发布于 2022-03-11 19:13:07
这是在
Hive 3.1.1
Spark 3.1.1您的堆栈溢出问题引起,我引用如下:
“我需要以编程的方式为Hive表和视图生成DDL语句。我试着用Spark和Beeline来完成这个任务。每条语句的直线时间大约为5-10秒,而斯派克在几毫秒内完成了同样的工作。我计划使用火花,因为它比直线更快。使用spark从hive获取DDL语句的一个缺点是,它将CHAR、VARCHAR字符视为字符串,并且不保留CHAR、VARCHAR数据类型的长度信息。同时直线保存CHAR、VARCHAR数据类型的数据类型和长度信息。我正在使用星火2.4.1和Beeline 2.1.1。在下面给出的示例create命令及其显示create输出。
在测试数据库中的Hive中创建一个简单的表
hive> use test;
OK
hive> create table etc(ID BIGINT, col1 VARCHAR(30), col2 STRING);
OK
hive> desc formatted etc;
# col_name data_type comment
id bigint
col1 varchar(30)
col2 string
# Detailed Table Information
Database: test
OwnerType: USER
Owner: hduser
CreateTime: Fri Mar 11 18:29:34 GMT 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://rhes75:9000/user/hive/warehouse/test.db/etc
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"col1\":\"true\",\"col2\":\"true\",\"id\":\"true\"}}
bucketing_version 2
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1647023374
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1现在让我们来看看火花壳
scala> spark.sql("show create table test.etc").show(false)
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|createtab_stmt |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|CREATE TABLE `test`.`etc` (
`id` BIGINT,
`col1` VARCHAR(30),
`col2` STRING)
USING text
TBLPROPERTIES (
'bucketing_version' = '2',
'transient_lastDdlTime' = '1647023374')
|
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+你可以看到星火显示正确的列
现在让我们通过直线在蜂箱中创建相同的表格。
0: jdbc:hive2://rhes75:10099/default> use test
No rows affected (0.019 seconds)
0: jdbc:hive2://rhes75:10099/default> create table etc(ID BIGINT, col1 VARCHAR(30), col2 STRING)
. . . . . . . . . . . . . . . . . . > No rows affected (0.304 seconds)
0: jdbc:hive2://rhes75:10099/default> desc formatted etc
. . . . . . . . . . . . . . . . . . > +-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| id | bigint | |
| col1 | varchar(30) | |
| col2 | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test | NULL |
| OwnerType: | USER | NULL |
| Owner: | hduser | NULL |
| CreateTime: | Fri Mar 11 18:51:00 GMT 2022 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://rhes75:9000/user/hive/warehouse/test.db/etc | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"col1\":\"true\",\"col2\":\"true\",\"id\":\"true\"}} |
| | bucketing_version | 2 |
| | numFiles | 0 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | totalSize | 0 |
| | transient_lastDdlTime | 1647024660 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | 1 |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
33 rows selected (0.159 seconds)现在再检查一下火花壳
scala> spark.sql("show create table test.etc").show(false)
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|createtab_stmt |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|CREATE TABLE `test`.`etc` (
`id` BIGINT,
`col1` VARCHAR(30),
`col2` STRING)
USING text
TBLPROPERTIES (
'bucketing_version' = '2',
'transient_lastDdlTime' = '1647024660')
|
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+看上去还行。因此,总之,您可以在Spark中得到列定义,因为您已经在Hive中定义了它们。
在你上面的声明中,我引用“我在使用星火2.4.1和Beeline 2.1.1",指的是较早版本的星火和蜂巢,它们可能有这样的问题。
https://stackoverflow.com/questions/71431757
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号