
从python中现有的分类列创建新列
从python中现有的分类列创建新列
提问于 2022-03-07 16:37:58
我正在尝试使用此表提取
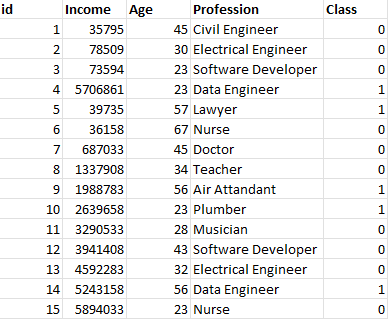
新列Profession_category和Age_category。
我的预期产出应该是这样的,在这样的行业里,折叠式的职业是土木工程师,电气工程师是工程师,软件开发人员,数据工程师,是计算护士,医生是健康的,其余的是“其他人”
回答 1
Stack Overflow用户
发布于 2022-03-07 17:19:42
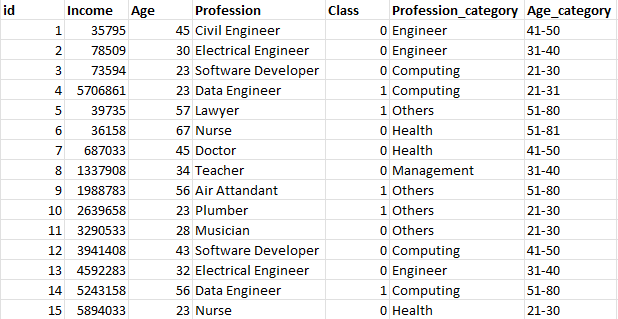
首先,我定义了一个与每个行业相关的字典,并使用apply()方法创建了一个名为"Profession_category"的新列,现在定义"Age_category"有点混乱,因为它们在一个特定的范围内,但我不知道如何计算,我使用了numpy.histogram并将df["Age"]作为输入数据,将年龄范围作为b传递给bins。“回收箱是一个序列,它定义了一个单调递增的bin边数组,包括最右边的边,允许非均匀的桶宽”,另一个选项是使用自定义的labels和年龄范围。
import pandas as pd
values = {'Civil Engineer': 'Engineer',
'Electrical Engineer': 'Engineer',
'Software Developer':'Computing',
'Data Engineer' : 'Computing',
'Nurse': 'Healt',
'Doctor': 'Healt'}
df["Profession_category"] = df["Profession"].apply(lambda x: values[x] if x in values else 'Others')
#b = [-1,15,40,60,80]
#df["Age_category"] = np.histogram(df['Age'], bins=b)[0].tolist()
bins= [i for i in range(15, 90, 10)]
labels = ['15-25','25-35','35-45', '45-55','55-65', '65-75', '75-85']
df['Age_category'] = pd.cut(df['Age'], bins=bins, labels=labels, right=False)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71384346
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号