
如何在Python中计算堆栈溢出数据转储的CSV文件中特定标记的频率
我最近从stackoverflow.com-Posts.7z下载了堆栈交换数据转储文件。在提取.7z文件时,我得到了一个Posts.xml文件,我使用GitHub上的"stackexchange-xml-转换器“工具将该文件转换为Posts.csv文件。Posts.csv文件包含在整个堆栈溢出网站上发布的所有帖子。Posts.csv文件的总大小为67 GB,因此在Microsoft、Visual、记事本等中打开它太大了。
CSV文件中的每个行(除了第一行,即标题行)都对应于与一个特定post关联的所有数据。例如,下面是与每个帖子关联的一些数据类别:Title、Tags、ContentLicense、ViewCount、CommentCount、CreationDate等等。每个数据类别都是CSV文件中自己的列。下面是一幅关于它的样子的图片:
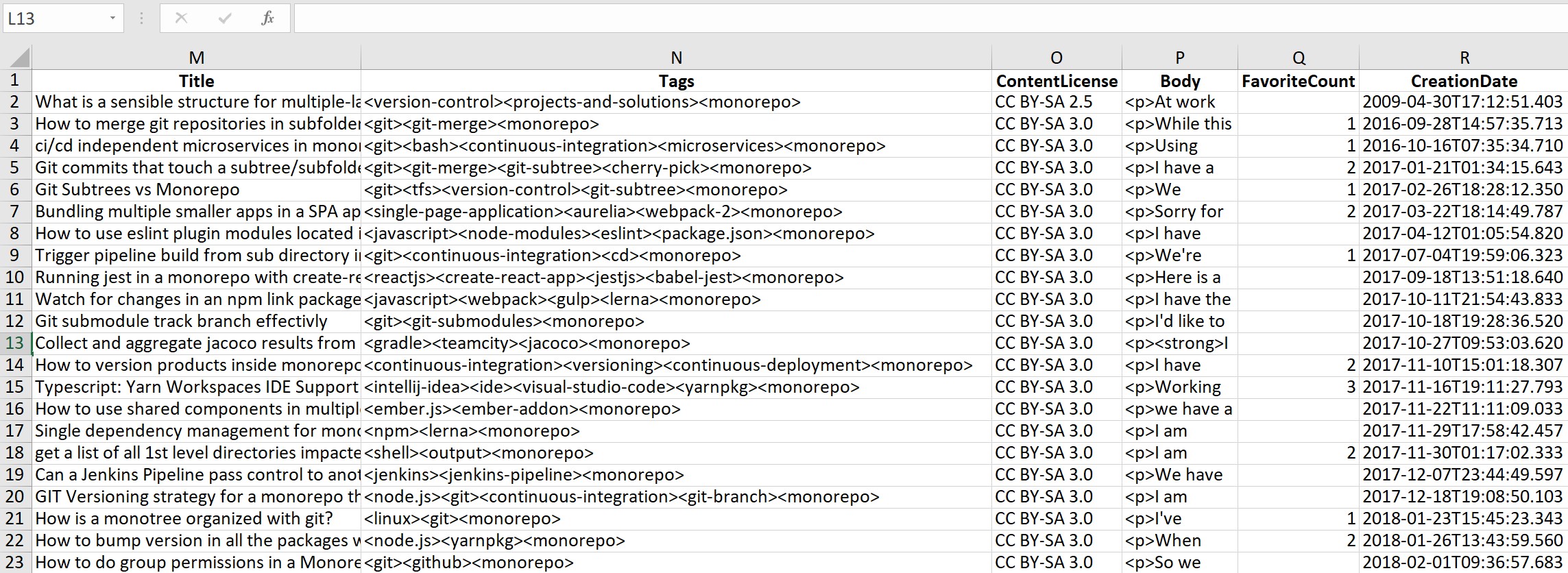
我的问题是,我试图计算Posts.csv文件中特定感兴趣的标记的频率,给出一个列表。例如,假设Python中有以下列表:
tagsOfInterest = ['version-control', 'git', 'git-merge', 'bash', 'microservices']仅在CSV文件的Tags 列中,我想计算标记version-control出现多少次、标记git出现多少次、标签git-merge出现多少次等等……
我一直在努力这样做,因为您会注意到,Tags列中的每一行都被格式化为一个连续字符串,每个不同的标记词都只有一个<>分隔。例如,在第一行中,一个帖子被标记为<version-control><projects-and-solutions><monorepo>。
我最初的尝试是先读取Posts.csv文件,然后将Tags列中的每一行添加到列表中,如下所示:
from pandas import *
import csv
# Read data
data = read_csv("Posts.csv")
# Add each row in the "Tags" column to a list:
tags_col = data['Tags'].tolist()然后我的想法就是标记每个标签词。但是,Posts.csv文件太大了,所以我的计算机在创建列表时内存不足!
作为,我的问题是:给出了一个感兴趣的标签列表,例如,tagsOfInterest = ['version-control', 'git', 'git-merge', 'bash', 'microservices'],如何从Posts.CSV文件的Tags列中计算列表中每个元素的频率?
回答 1
Stack Overflow用户
发布于 2022-03-07 02:24:26
import csv
from collections import Counter
counts = Counter()
for row in csv.reader(open('Posts.csv')):
for tag in row[1].lstrip('<').rstrip('>').split('><'):
counts[tag] += 1
print(counts)如果需要,可以使用DictReader,使用row['Tags']而不是row[1]。
https://stackoverflow.com/questions/71375771
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号