
Java设计模式(编排/工作流)
我需要在事件发生后自动化工作流。我确实有CRUD应用程序的经验,但没有工作流/批处理方面的经验。在设计系统时需要帮助。
需求
工作流包括5个步骤。每个步骤都是一个REST调用,并且依赖于前面的步骤。步骤实例:(VerifyIfUserInSystem,CreateUserIfNeeded,EnrollInOpt1,EnrollInOpt2,.)
我的想法是维护两个DB表。
- WORKFLOW_STATUS表,包含如下列(外键(引用主表)、工作流状态:(新建、进程、完成、失败)、完成步骤:(STEP1、STEP2、.)、处理时间、.)
- EVENT_LOG表用于维护特定记录(外键、步骤、ExceptionLog)的事件/异常跟踪
问题
#1.这是一个正确的方法来编排系统(这不是那么复杂)吗?
#2.由于步骤涉及REST调用,所以当服务不可用时,我可能不得不停止该进程,并在稍后的时间点继续该过程。我不确定是否应该进行多次重试,以及在将其标记为失败之前如何维持不尝试。(猜测在WORKFLOW_STATUS表中创建另一个名为RETRY_ATTEMPT的列,并在标记失败之前设置一些限制)
#3 EVENT_LOG表是一个正确的设计吗?对于异常日志,我应该使用什么数据类型(clob或varchar(2048年))?每个步骤/重试尝试都将作为新记录插入到此表中。
#4如何在依赖服务备份后重置/重新启动失败的条目。
如果有的话,请给我一个博客/视频/资源。提前谢谢。
回答 2
Stack Overflow用户
发布于 2022-04-01 08:19:02
您将描述一个企业集成模式,它包含来自REST调用的丰富/转换和结果的有状态聚合(因此,许多这样的流可能在任何时候都在进行)。阿帕奇骆驼正是针对这些场景而设计的。
请参阅阿帕奇骆驼到底是什么?
Stack Overflow用户
发布于 2022-03-07 18:32:56
你有没有考虑过使用像Netflix的导体一样的工作流编排引擎?文档,Github。
售票员配备了许多你正在寻找内置的功能。
下面是一个使用两个顺序HTTP请求(第二个请求需要来自第一个请求的响应)的示例工作流:
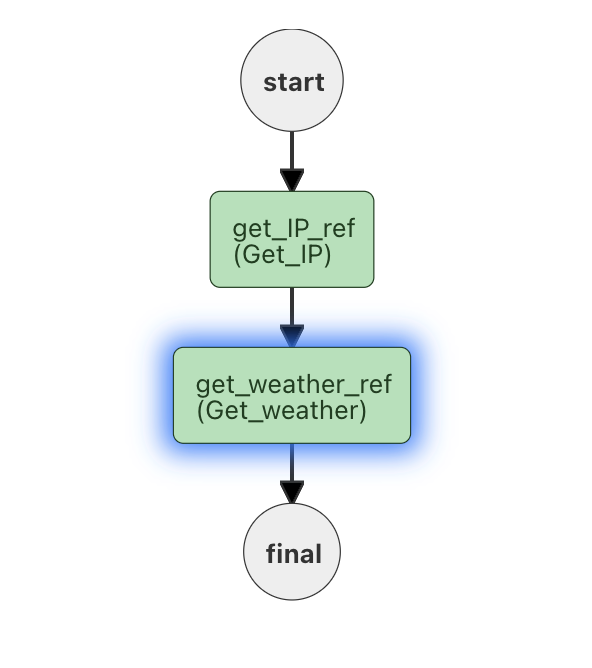
输入提供了一个IP地址(和一个Accuweather键)
{
"ipaddress": "98.11.11.125"
}- HTTP请求1定位IP地址的zipCode。
- 2使用ZipCode (和每个uses )来报告天气。
此工作流的输出是:
{
"zipcode": "04043",
"forecast": "rain"
}你的问题:
- 我会用像指挥一样的编曲工具。
- 这些任务中的每一个(在导体中定义)都内置了重试逻辑。您的实现方式在预期的时间等方面会有所不同。因为我在这里调用的2个API都是公共的(而且相对较快),所以在重试之间等待的时间不长:
"retryCount": 3,
"retryLogic": "FIXED",
"retryDelaySeconds": 5,在连接内部,可以调整更多的参数:
"connectionTimeOut": 1600,
"readTimeOut": 1600如果需要,还有指数重试逻辑。
- 事件日志存储在ElasticSearch中。
- 您可以为所有工作流构建错误路径。
我已经在导体游乐场中启动并运行了这个称为"Stack_overflow_sequential_http“的工作流。创建一个免费帐户。运行工作流--单击“运行工作流,选择"Stack_overflow_sequential_http”并使用上面的JSON查看它的运行情况。
get_weather连接是一个非常慢的API,因此在成功之前它可能会失败几次。复制工作流,并使用超时值来提高成功。
https://stackoverflow.com/questions/71370237
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号