
R中的计算公式
R中的计算公式
提问于 2022-03-05 19:39:48
我想要一些帮助解决一个涉及R软件的微积分问题。我做了一部分,但我不太理解另一部分,所以我希望你的帮助。
我使用三种多标准方法(MCDM) (我将称之为M1、M2和M3 )来生成排名,这是result数据库。这是第一步。
result<-structure(list(n = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27,
28, 29), M1 = c(29L, 1L, 28L, 27L, 25L, 26L, 24L, 20L, 21L,
22L, 23L, 15L, 12L, 17L, 18L, 19L, 16L, 13L, 14L, 5L, 6L, 7L,
8L, 9L, 10L, 11L, 4L, 2L, 3L), M2 = c(1, 29, 28, 27, 26, 25,
24, 23, 22, 21, 20, 15, 12, 19, 18, 17, 16, 14, 13, 11, 10, 9,
8, 7, 6, 5, 4, 3, 2), M3 = c(1L, 29L, 28L, 27L, 25L, 26L, 24L,
20L, 21L, 22L, 23L, 15L, 12L, 17L, 18L, 19L, 16L, 13L, 14L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 4L,
2L, 3L)), class = "data.frame", row.names = c(NA,-29L))
> result
n M1 M2 M3
1 1 29 1 1
2 2 1 29 29
3 3 28 28 28
4 4 27 27 27
5 5 25 26 25
6 6 26 25 26
7 7 24 24 24
8 8 20 23 20
9 9 21 22 21
10 10 22 21 22
11 11 23 20 23
12 12 15 15 15
13 13 12 12 12
14 14 17 19 17
15 15 18 18 18
16 16 19 17 19
17 17 16 16 16
18 18 13 14 13
19 19 14 13 14
20 20 5 11 5
21 21 6 10 6
22 22 7 9 7
23 23 8 8 8
24 24 9 7 9
25 25 10 6 10
26 26 11 5 11
27 27 4 4 4
28 28 2 3 2
29 29 3 2 3第二步利用Spearman’s rank correlation coefficient为每个MCDM方法寻找权值。Spearman’s rank correlation coefficient在kth和ith MCDM方法之间的计算公式如下:
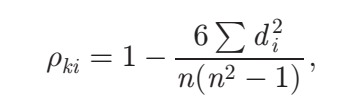
其中,n是备选方案的数量,di是两种MCDM方法的级别之间的差异。
所以我确实喜欢这样:
pki<-cor(result[,2:4], method = "spearman")
> pki
M1 M2 M3
M1 1.0000000 0.5778325 0.6137931
M2 0.5778325 1.0000000 0.9640394
M3 0.6137931 0.9640394 1.0000000第三步是:根据pki值,计算kth方法与其他MCDM方法的平均相似性:
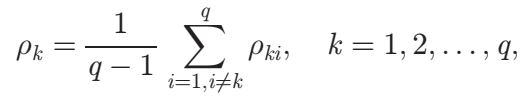
其中q是MCDM方法的数量。
第三步我不太明白,所以我不知道怎么做,你能帮我吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-05 20:04:46
也许:
rho2 <-rho # “pki” -> rho[k,i]
diag(rho2) <- 0
rowSums(rho2)/2 # 1/(3-1) == 2请注意,当讨论R时,“公式”一词并不适用于R,即数学方程实际上描述了一组数学运算。R公式有几种用途,其中最适用的是描述模型结构。如果试图将表达式或函数封装到单个对象中,则搜索的最接近的术语可能是表达式或函数。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71365428
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号