
在Excel中计算F1分数
在Excel中计算F1分数
提问于 2022-03-05 19:29:35
在统计中
如果预测值为1,而原始值为1,则称为真正(TP)。
如果预测值为0,原始值为1,则为假阴性(FN)。
如果预测值为1,原始值为0,则为假阳性(FP)。
如果预测为0,原始值为0,则为真负(TN)。
F1评分是衡量两个数据集之间关系的一种方法。
它的计算方式如下

我有一个文件,其中包含1000+预测的结果,每个值要么为0,要么为1。
看上去像这样
Label 0 1 2 .... 0 1 2 ...
--------------------------------------------------
0 0 1 0 1 1
1 0 0 1 0 1
0 1 1 0 0 0
0 0 1 0 1 1
1 0 0 0 0 0
1 0 1 0 1 1
0 0 1 1 0 1
1 1 1 1 1 0
0 1 0 1 0 1
1 1 0 0 0 1
1 0 0 0 1 0
1 1 0 1 1 1
0 1 1 1 0 1
0 0 1 0 1 1
0 1 0 1 0 0
1 1 0 0 1 0
0 1 1 1 1 1
0 0 0 1 0 0
0 0 1 0 1 1
0 1 1 1 0 0 我唯一能想到的方法是有一个1000+新列来检测TP,另一个用来检测FP和anorger 1000用于TN,另外1000个用于FN。
其中,对于TP,每个方程=if(和(B6=NB6,B6=1),1,0)等等。
这不是一个好的解决办法。
是否有一种更快、更容易获得这些列的F1分数的方法,或者更好的F1评分--微观和宏?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-05 22:38:38
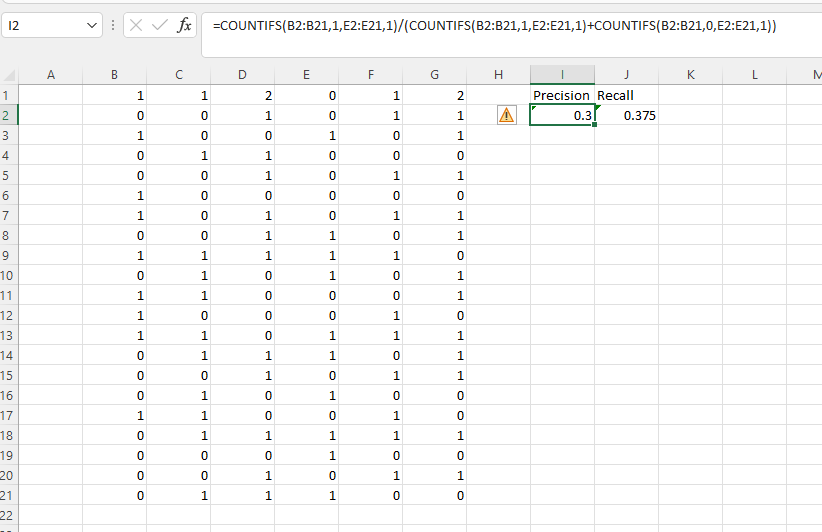
我今晚不会讲完,但我认为测试数据B和E列的公式是
精度:
=COUNTIFS(B2:B21,1,E2:E21,1)/(COUNTIFS(B2:B21,1,E2:E21,1)+COUNTIFS(B2:B21,0,E2:E21,1))召回
=COUNTIFS(B2:B21,1,E2:E21,1)/(COUNTIFS(B2:B21,1,E2:E21,1)+COUNTIFS(B2:B21,1,E2:E21,0))你可以用同样的方式让其他人
编辑
为了清晰起见,我建议使用命名范围。这些范围将锚定在一组特定的行上,这些行可以是动态的,但是会引用不同的列,因为它们被拖过如下所示。
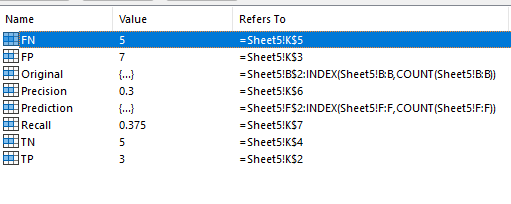
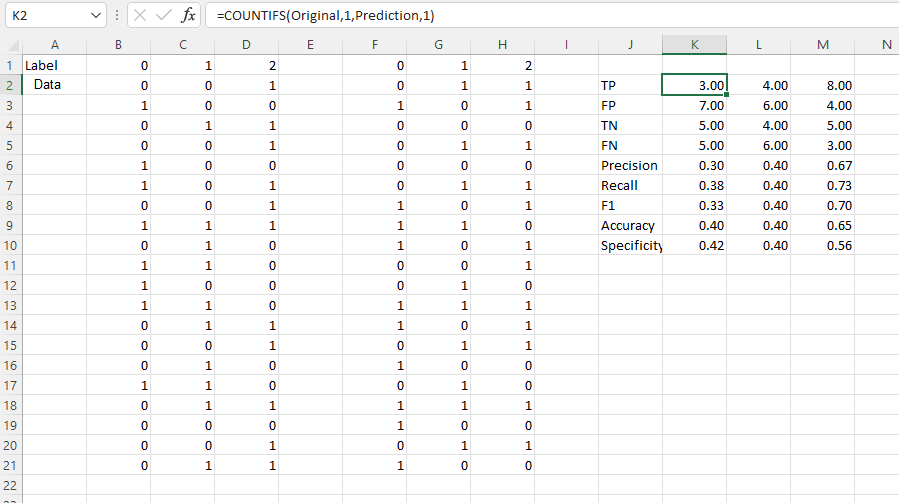
然后,您可以使用这样的公式进行TP。
=COUNTIFS(Original,1,Prediction,1)和
=TP/(TP+FP)为了精确。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71365367
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号