
链接:对于嵌套的RowRowConverter,DataTypes似乎失败了
我试图从本地加载一个复杂的JSON文件(多个不同的数据类型、嵌套的对象/数组等),使用表API文件系统连接器将它们作为源代码读取,然后将它们放到DataStream中,然后执行一些操作(为了简洁起见,此处不显示)。
转换给我一个DataStream[Row]类型的DataStream[Row],我需要将它转换为DataStream[RowData] (为了接收器的目的,这里不详细介绍)。值得庆幸的是,有一个RowRowConverter实用程序可以帮助完成这个映射。当我尝试一个完全平坦的JSON时,它可以工作,但是当我在JSON中引入数组和映射时,它就不再起作用了。
下面是抛出的异常-空指针异常:
at org.apache.flink.table.data.conversion.ArrayObjectArrayConverter.allocateWriter(ArrayObjectArrayConverter.java:140)
at org.apache.flink.table.data.conversion.ArrayObjectArrayConverter.toBinaryArrayData(ArrayObjectArrayConverter.java:114)
at org.apache.flink.table.data.conversion.ArrayObjectArrayConverter.toInternal(ArrayObjectArrayConverter.java:93)
at org.apache.flink.table.data.conversion.ArrayObjectArrayConverter.toInternal(ArrayObjectArrayConverter.java:40)
at org.apache.flink.table.data.conversion.DataStructureConverter.toInternalOrNull(DataStructureConverter.java:61)
at org.apache.flink.table.data.conversion.RowRowConverter.toInternal(RowRowConverter.java:75)
at flink.ReadJsonNestedData$.$anonfun$main$2(ReadJsonNestedData.scala:48)有趣的是,当我设置我的断点和调试器时,我发现了这一点:RowRowConverter::toInternal,第一次被称为works,将一直深入到ArrayObjectArrayConverter::allocateWriter()
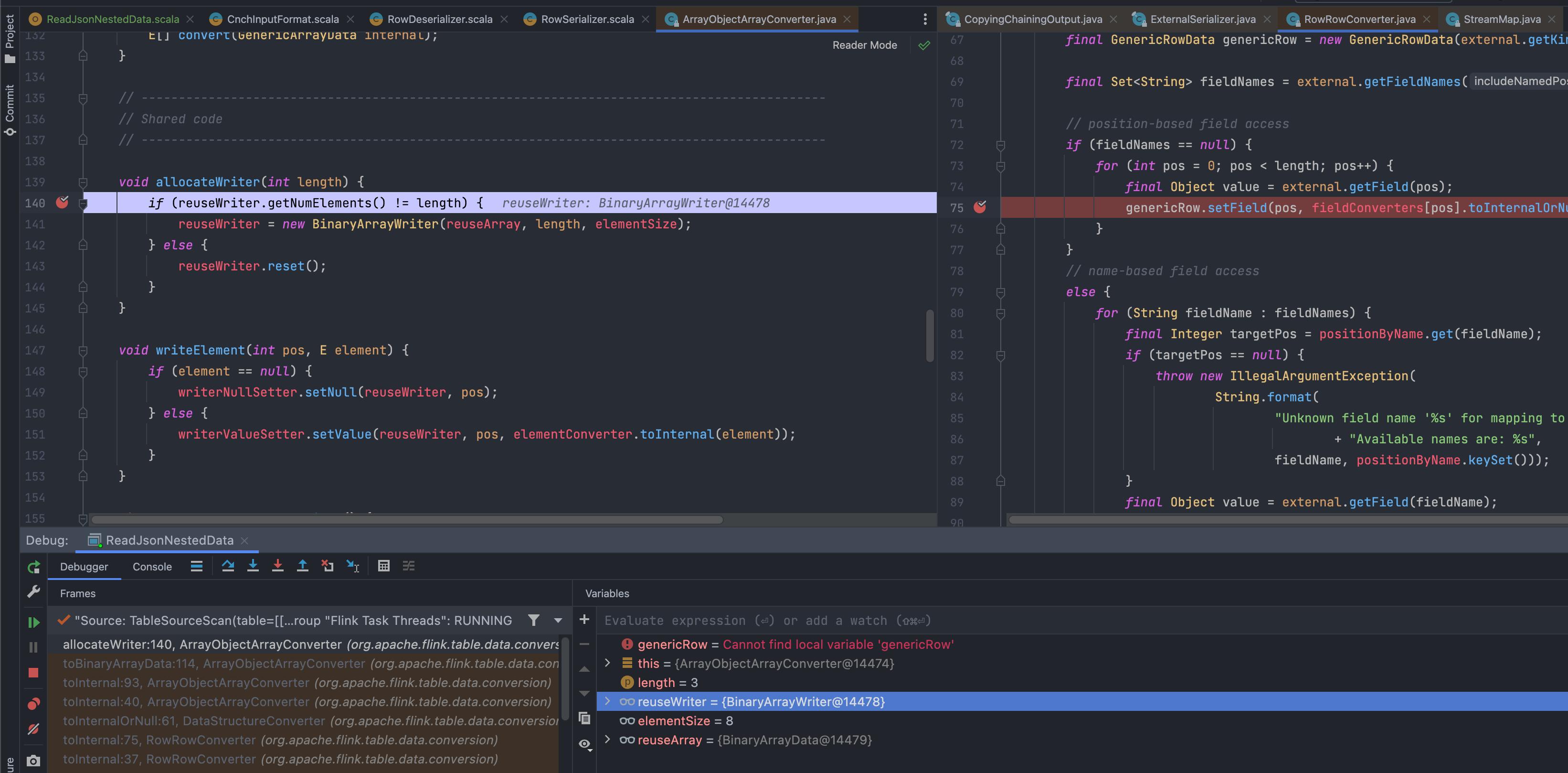
然而,由于一些奇怪的原因,RowRowConverter::toInternal运行了两次,如果我继续前进,它最终会回到这里,这就是出现空指针异常的地方。
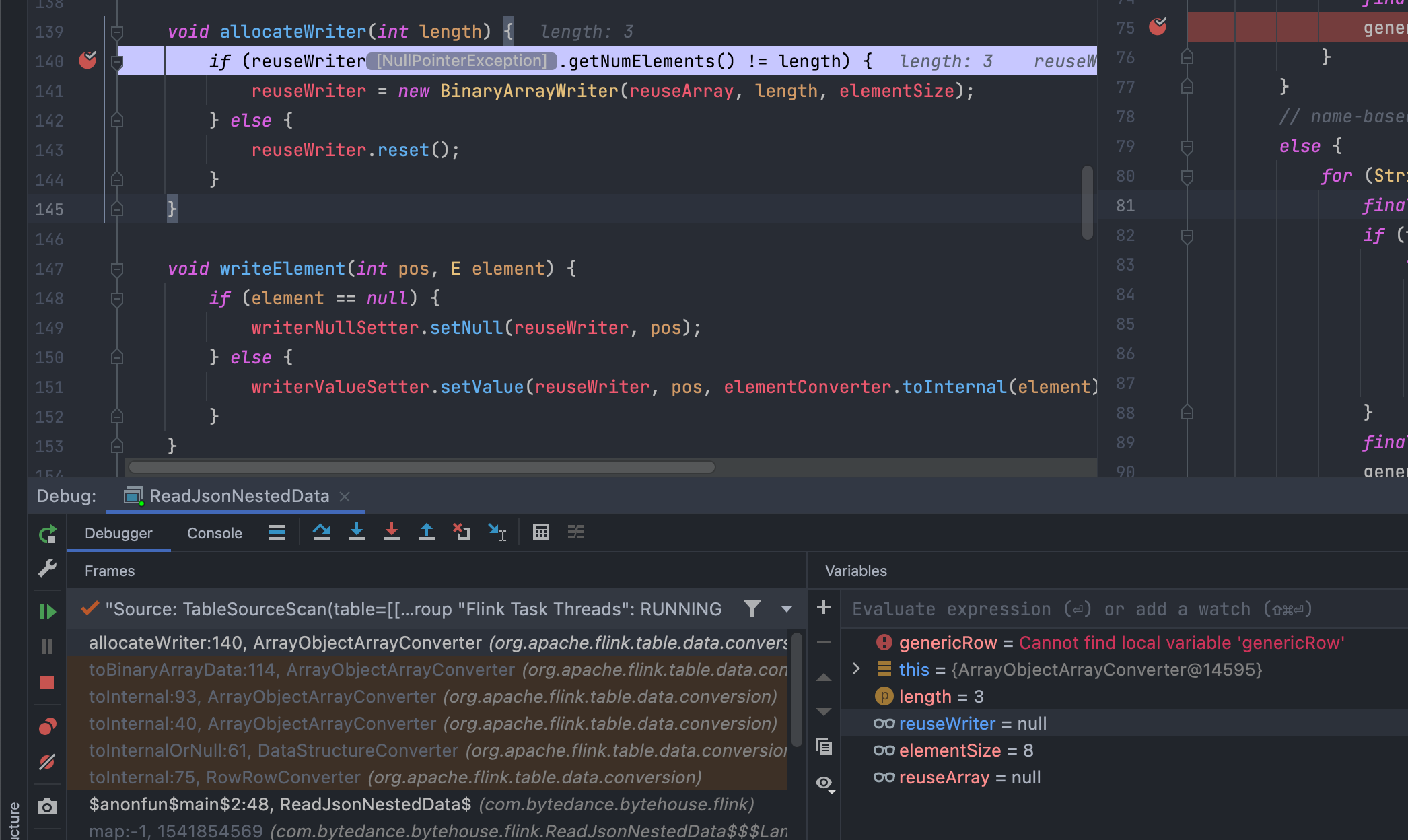
JSON的示例(为了简洁,只简化了一个嵌套的JSON)。我把它放在我的/src/main/resources文件夹里
{"discount":[670237.997082,634079.372133,303534.821218]}import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment
import org.apache.flink.table.data.conversion.RowRowConverter
import org.apache.flink.table.types.FieldsDataType
import org.apache.flink.table.types.logical.RowType
import scala.collection.JavaConverters._
object ReadJsonNestedData {
def main(args: Array[String]): Unit = {
// setup
val jsonResource = getClass.getResource("/NESTED.json")
val jsonFilePath = jsonResource.getPath
val tableName = "orders"
val readJSONTable =
s"""
| CREATE TABLE $tableName (
| `discount` ARRAY<DECIMAL(12, 6)>
| )WITH (
| 'connector' = 'filesystem',
| 'path' = '$jsonFilePath',
| 'format' = 'json'
|)""".stripMargin
val colFields = Array(
"discount"
)
val defaultDataTypes = Array(
DataTypes.ARRAY(DataTypes.DECIMAL(12, 6))
)
val rowType = RowType.of(defaultDataTypes.map(_.getLogicalType), colFields)
val defaultDataTypesAsList = defaultDataTypes.toList.asJava
val dataType = new FieldsDataType(rowType, defaultDataTypesAsList)
val rowConverter = RowRowConverter.create(dataType)
// Job
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val tableEnv = StreamTableEnvironment.create(env)
tableEnv.executeSql(readJSONTable)
val ordersTable = tableEnv.from(tableName)
val dataStream = tableEnv
.toDataStream(ordersTable)
.map(row => rowConverter.toInternal(row))
dataStream.print()
env.execute()
}
}因此,我想知道:
RowRowConverter不起作用的原因以及我如何补救- 为什么
RowRowConverter::toInternal为同一个Row运行了两次。这可能是导致NullPointerException的原因 - 如果基于上面的代码,实例化和使用
RowRowConverter的方法是正确的。
谢谢!
环境:
- IntelliJ 2021.3.2 (终极版)
- AdoptOpenJDK
1.8 - Scala:
2.12.15 - Flink:
1.13.5 - 使用的Flink库(在本例中):
flink-table-api-java-bridgeflink-table-planner-blinkflink-clientsflink-json
回答 2
Stack Overflow用户
发布于 2022-03-07 07:15:15
RowRowConverter::toInternal的第一个调用是一个内部实现,用于对表源发出的StreamRecord进行深度复制,该副本独立于映射函数中的转换器。其原因是映射函数中的RowRowConverter不通过调用RowRowConverter::open来初始化。您可以使用RichMapFunction来调用RichMapFunction::open中的RowRowConverter::open。
Stack Overflow用户
发布于 2022-03-07 09:12:35
谢谢@renqs的回答。
这是代码,如果有人感兴趣的话。
class ConvertRowToRowDataMapFunction(fieldsDataType: FieldsDataType)
extends RichMapFunction[Row, RowData] {
private final val rowRowConverter = RowRowConverter.create(fieldsDataType)
override def open(parameters: Configuration): Unit = {
super.open(parameters)
rowRowConverter.open(this.getClass.getClassLoader)
}
override def map(row: Row): RowData =
this.rowRowConverter.toInternal(row)
}
// at main function
// ... continue from previous
val dataStream = tableEnv
.toDataStream(personsTable)
.map(new ConvertRowToRowDataMapFunction(dataType))https://stackoverflow.com/questions/71350856
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号