
如何理解learner.lr_plot在ktrain软件包中的丢失率(对数量表)图?
如何理解learner.lr_plot在ktrain软件包中的丢失率(对数量表)图?
提问于 2022-03-02 05:58:58
我正在使用text包对文本进行分类。我的实验显示如下:
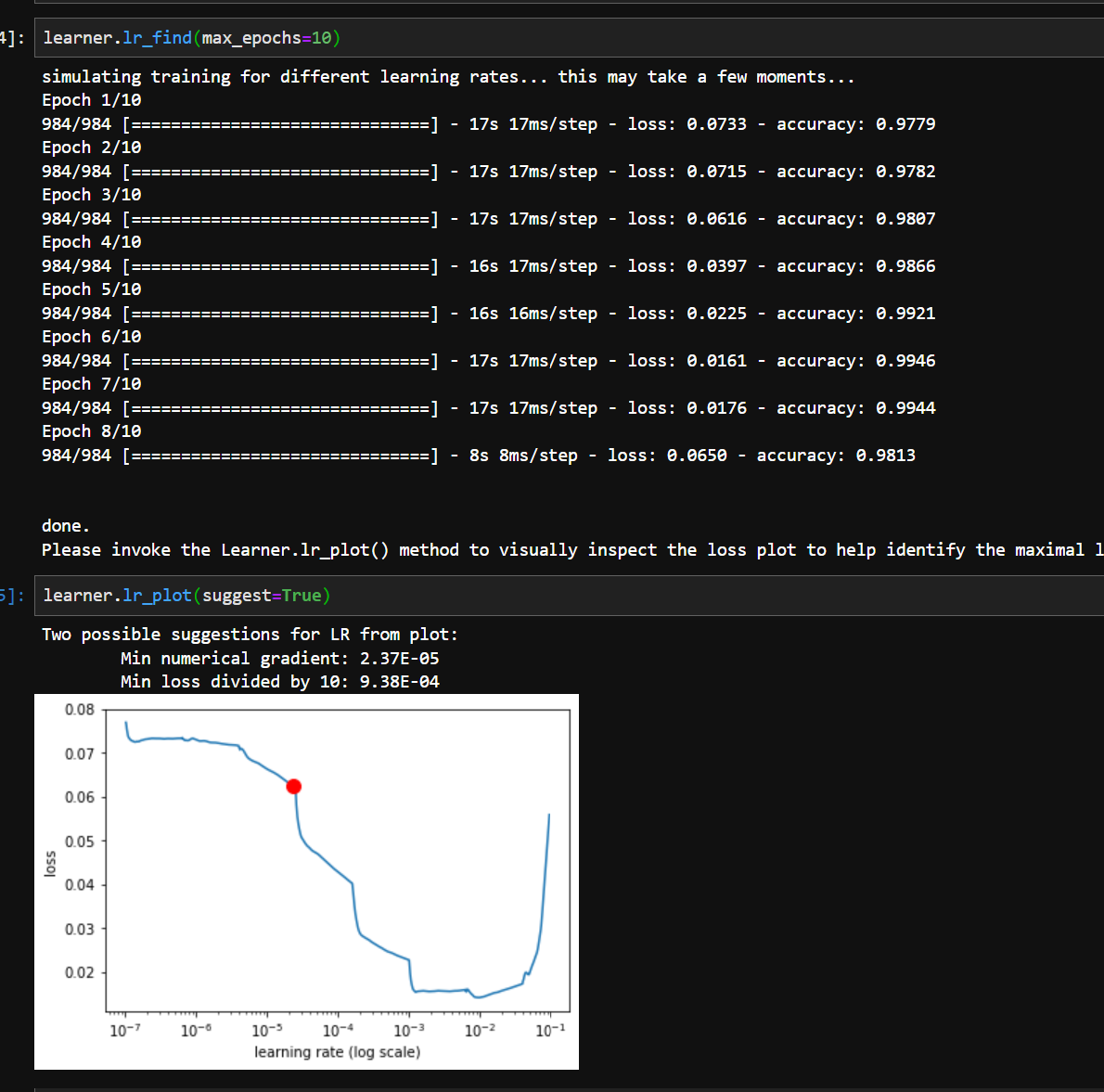
lr_find和lr_plot是ktrain中的函数。它们可以用来突出显示最佳学习率,这是显示在情节中的红点。
我不明白如何理解这个阴谋:
- 如何将测井标度转换为正线性标度?
- 为什么最好的比例尺是红点?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-08 00:53:32
正如lr_find方法中的文本所述,您可以直观地查看图,并在损失在发散之前下降的范围内选择一个学习速率。在这一范围内,较高的学习速度将更快地收敛。这是来自莱斯利·史密斯的论文的一个名为"LR范围测试“的想法,它在费莱库中很流行,后来被其他库采用,比如克列和亚马逊的胶子库。这幅图中的红点只是损失急剧下降的数值近似,对于自动化场景可能有用,但不一定是最好的。在这幅图中,红色点代表曲线中最陡峭的部分,这是一种自动从图中选择学习率的策略(没有视觉检查)。其他自动化策略包括获取与最小损失相关的学习速率,除以10,以及找到与最长谷相关的学习速率。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71318065
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号