
如何在javascript中获得字母的重音/音素?
我想在javascript中得到字母的重音/对话框。
例如:
ñ->~á->´è->`
我试过使用.normalize("NFD"),但它没有返回正确的重音/diacritc
string = "á"
string.normalize("NFD").split("")
// ['a', '́']
string.normalize("NFD").split("").includes("´")
// false
'́' === "´"
// false我希望NFD或任何其他函数给出重音/对话式,而不是组合的重音/对话式。
回答 2
Stack Overflow用户
发布于 2022-03-07 13:20:12
规范分解(NFD)确实有效:
let accent = '\u0301';
console.log(`Accute accent: ${accent}`);
let out = 'á'.normalize('NFD').split('').includes(accent);
console.log(out);
扩展演示:您不必维护所有字符的地图。在演示中,地图只被用来获得解说词的描述。
const dc = getDiacritics();
let inputString = 'n\u0303 \u00F1áèâäåçč السّلَامُ عَلِيْكُمُ';
inputString = inputString.normalize('NFD');
inpt.innerText = inputString;
out.innerHTML = getWholeChars(inputString).map(c => {
let chars = c.split('');
return `${c} -> <span>${chars[1] + '\u25cc'}</span> ${dc[chars[1]]}\n`;
}).join('');
// get characters with diacritics
function getWholeChars(str) {
// add diacritics to the expression to extend capabilities
var re = /.[\u064b-\u065F]+|.[\u0300-\u036F]+/g;
var match, matches = [];
while (match = re.exec(str))
matches.push(match[0]);
return matches;
}
// list taken from
// https://en.wikipedia.org/wiki/Combining_Diacritical_Marks
// And
// https://en.wikipedia.org/wiki/Arabic_script_in_Unicode
function getDiacritics() {
return {
'\u0300': 'Grave Accent',
'\u0301': 'Acute Accent',
'\u0302': 'Circumflex Accent',
'\u0303': 'Tilde',
'\u0304': 'Macron',
'\u0305': 'Overline',
'\u0306': 'Breve',
'\u0307': 'Dot Above',
'\u0308': 'Diaeresis',
'\u0309': 'Hook Above',
'\u030A': 'Ring Above',
'\u030B': 'Double Acute Accent',
'\u030C': 'Caron',
'\u030D': 'Vertical Line Above',
'\u030E': 'Double Vertical Line Above',
'\u030F': 'Double Grave Accent',
'\u0310': 'Candrabindu',
'\u0311': 'Inverted Breve',
'\u0312': 'Turned Comma Above',
'\u0313': 'Comma Above',
'\u0314': 'Reversed Comma Above',
'\u0315': 'Comma Above Right',
'\u0316': 'Grave Accent Below',
'\u0317': 'Acute Accent Below',
'\u0318': 'Left Tack Below',
'\u0319': 'Right Tack Below',
'\u031A': 'Left Angle Above',
'\u031B': 'Horn',
'\u031C': 'Left Half Ring Below',
'\u031D': 'Up Tack Below',
'\u031E': 'Down Tack Below',
'\u031F': 'Plus Sign Below',
'\u0320': 'Minus Sign Below',
'\u0321': 'Palatalized Hook Below',
'\u0322': 'Retroflex Hook Below',
'\u0323': 'Dot Below',
'\u0324': 'Diaeresis Below',
'\u0325': 'Ring Below',
'\u0326': 'Comma Below',
'\u0327': 'Cedilla',
'\u0328': 'Ogonek',
'\u0329': 'Vertical Line Below',
'\u032A': 'Bridge Below',
'\u032B': 'Inverted Double Arch Below',
'\u032C': 'Caron Below',
'\u032D': 'Circumflex Accent Below',
'\u032E': 'Breve Below',
'\u032F': 'Inverted Breve Below',
'\u0330': 'Tilde Below',
'\u0331': 'Macron Below',
'\u0332': 'Low Line',
'\u0333': 'Double Low Line',
'\u0334': 'Tilde Overlay',
'\u0335': 'Short Stroke Overlay',
'\u0336': 'Long Stroke Overlay',
'\u0337': 'Short Solidus Overlay',
'\u0338': 'Long Solidus Overlay',
'\u0339': 'Right Half Ring Below',
'\u033A': 'Inverted Bridge Below',
'\u033B': 'Square Below',
'\u033C': 'Seagull Below',
'\u033D': 'X Above',
'\u033E': 'Vertical Tilde',
'\u033F': 'Double Overline',
'\u0340': 'Grave Tone Mark',
'\u0341': 'Acute Tone Mark',
'\u0342': 'Greek Perispomeni',
'\u0343': 'Greek Koronis',
'\u0344': 'Greek Dialytika Tonos',
'\u0345': 'Greek Ypogegrammeni',
'\u0346': 'Bridge Above',
'\u0347': 'Equals Sign Below',
'\u0348': 'Double Vertical Line Below',
'\u0349': 'Left Angle Below',
'\u034A': 'Not Tilde Above',
'\u034B': 'Homothetic Above',
'\u034C': 'Almost Equal To Above',
'\u034D': 'Left Right Arrow Below',
'\u034E': 'Upwards Arrow Below',
'\u034F': 'Grapheme Joiner',
'\u0350': 'Right Arrowhead Above',
'\u0351': 'Left Half Ring Above',
'\u0352': 'Fermata',
'\u0353': 'X Below',
'\u0354': 'Left Arrowhead Below',
'\u0355': 'Right Arrowhead Below',
'\u0356': 'Right Arrowhead And Up Arrowhead Below',
'\u0357': 'Right Half Ring Above',
'\u0358': 'Dot Above Right',
'\u0359': 'Asterisk Below',
'\u035A': 'Double Ring Below',
'\u035B': 'Zigzag Above',
'\u035C': 'Double Breve Below',
'\u035D': 'Double Breve',
'\u035E': 'Double Macron',
'\u035F': 'Double Macron Below',
'\u0360': 'Double Tilde',
'\u0361': 'Double Inverted Breve',
'\u0362': 'Double Rightwards Arrow Below',
'\u0363': 'Latin Small Letter A',
'\u0364': 'Latin Small Letter E',
'\u0365': 'Latin Small Letter I',
'\u0366': 'Latin Small Letter O',
'\u0367': 'Latin Small Letter U',
'\u0368': 'Latin Small Letter C',
'\u0369': 'Latin Small Letter D',
'\u036A': 'Latin Small Letter H',
'\u036B': 'Latin Small Letter M',
'\u036C': 'Latin Small Letter R',
'\u036D': 'Latin Small Letter T',
'\u036E': 'Latin Small Letter V',
'\u036F': 'Latin Small Letter X',
'\u064B': 'Arabic Fathatan',
'\u064C': 'Arabic Dammatan',
'\u064D': 'Arabic Kasratan',
'\u064E': 'Arabic Fatha',
'\u064F': 'Arabic Damma',
'\u0650': 'Arabic Kasra',
'\u0651': 'Arabic Shadda',
'\u0652': 'Arabic Sukun',
'\u0653': 'Arabic Maddah Above',
'\u0654': 'Arabic Hamza Above',
'\u0655': 'Arabic Hamza Below',
'\u0656': 'Arabic Subscript Alef',
'\u0657': 'Arabic Inverted Damma',
'\u0658': 'Arabic Mark Noon Ghunna',
'\u0659': 'Arabic Zwarakay',
'\u065A': 'Arabic Vowel Sign Small V Above',
'\u065B': 'Arabic Vowel Sign Inverted Small V Above',
'\u065C': 'Arabic Vowel Sign Dot Below',
'\u065D': 'Arabic Reversed Damma',
'\u065E': 'Arabic Fatha With Two Dots',
'\u065F': 'Arabic Wavy Hamza Below',
};
}body {
padding: 1rem;
}
pre>span {
font-size: 2rem;
font-weight: bold;
}
#inpt {
font-family: 'Courier New', Courier, monospace;
font-weight: bold;
font-size: 2rem;
}Input: <span id="inpt"></span>
<pre id="out"></pre>
对于其他语言,在getWholeChars中的正则表达式中添加diacritics。
Stack Overflow用户
发布于 2022-03-08 10:32:52
使用获取字母string.normalize("NFD").split("")的重音/对话框的方法是正确的string.normalize("NFD").split("")。
normalize("NFD")返回正确的结果,在本例中是结合急性口音 UnicodeDecimalCodé。
但是,您要做的是比较来自á ( normalize("NFD") )的字母的输出,它是结合了急性口音 (char code 769)和正常急性口音 (char code 180)。当然,这是两个不同的字母。
这同样适用于字母è,它具有结合严肃口音 (char代码768);您正在将其与我们使用并在键盘上键入的正常的坟墓口音 (char code 96)进行比较;它们是两个不同的字母。
独立字母(正常的)字母(包括急性口音字母和严肃口音字母)将始终是单独的字母,即使它们出现在字符串中的任何其他字母之前或之后。然而,组合形式的字母(它们有不同的字符代码来区分它们)将位于它们相邻的下一个或上一个字母的上方或下面。这在阿拉伯口音字母和希伯来语等其他语言中也是类似的。
以下是一些倾斜字母的比较:
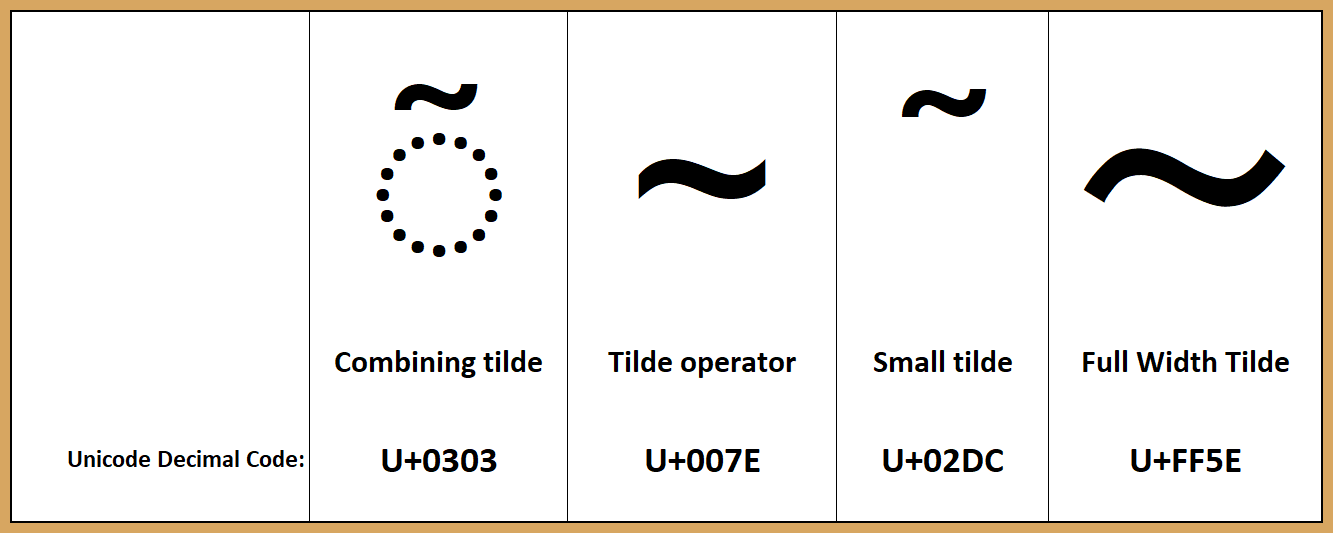
见下面的例子:
console.log("á".normalize("NFD").split("")[1].charCodeAt()); // 769 code for Combining Acute Accent
console.log("´".charCodeAt()); // 180 code for Normal Acute Accent
console.log("è".normalize("NFD").split("")[1].charCodeAt()); // 768 Combining Grave Accent
console.log("`".charCodeAt()); // 96 Normal Grave Accent
console.log("á".normalize("NFD").split("")[1].charCodeAt()); // 769 code for Combining Acute Accent
console.log("´".charCodeAt()); // 180 code for Normal Acute Accent
console.log("è".normalize("NFD").split("")[1].charCodeAt()); // 768 Combining Grave Accent
console.log("`".charCodeAt()); // 96 Normal Grave Accent
https://stackoverflow.com/questions/71315832
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号