
Scopus抽象检索-只有在解析了太多条目时才会出现值和类型错误
我试图通过Scopus抽象检索检索摘要。我有一个带有3590个EID的文件。
import pandas as pd
import numpy as np
file = pd.read_excel(r'C:\Users\Amanda\Desktop\Superset.xlsx', sheet_name='Sheet1')
from pybliometrics.scopus import AbstractRetrieval
for i, row in file.iterrows():
q = row['EID']
ab = AbstractRetrieval(q,view='META_ABS')
file.at[i,"Abstract"] = ab.description
print(str(i) + ' ' + ab.description)
print(str(''))我得到了一个值错误-

作为对值错误的响应,我修改了代码。
from pybliometrics.scopus import AbstractRetrieval
error_index_valueerror = {}
for i, row in file.iterrows():
q = row['EID']
try:
ab = AbstractRetrieval(q,view='META_ABS')
file.at[i,"Abstract"] = ab.description
print(str(i) + ' ' + ab.description)
print(str(''))
except ValueError:
print(f"{i} Value Error")
error_index_valueerror[i] = row['Title']
continue当我用10-15个条目测试这段代码时,它工作得很好,我检索了所有的摘要。但是,当我使用3590个EID运行实际文件时,在类型错误(‘只能将str (而不是"NoneType")连接到str曲面)之前,输出将是一系列10-12值错误。
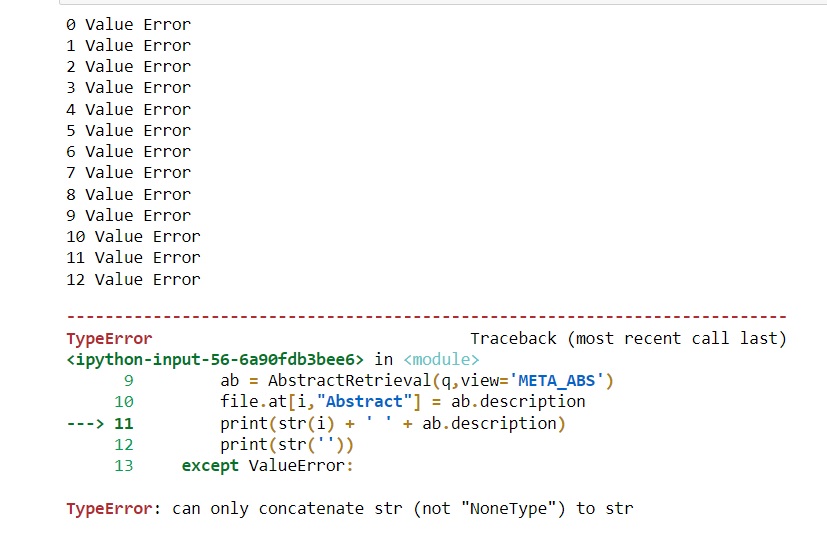
我不知道如何继续处理这个问题。如有任何关于这件事的建议,我们将不胜感激!
(附带注意:当我更改视图=‘FULL’(如文档所建议的)时,我仍然得到相同的结果。)
回答 1
Stack Overflow用户
发布于 2022-02-27 08:27:17
如果没有EID检查,就很难指出确切的原因。但是,我确信您的问题缺少了.description属性中的抽象。当第一个调用为空时,就足够了,因为它将将列类型转换为float,您希望在其中附加一个字符串。错误就是这么说的。
因此,您的问题与计量学或Scopus无关,而是与您显示代码的方式有关。
试一试:
import pandas as pd
import numpy as np
from pybliometrics.scopus import AbstractRetrieval
def parse_abstract(eid):
"""Retrieve Abstract of a document."""
ab = AbstractRetrieval(q, view='META_ABS')
return ab.description or ab.abstract
FNAME = r'C:\Users\Amanda\Desktop\Superset.xlsx'
df = pd.read_excel(FNAME, sheet_name='Sheet1')
df["abstract"] = df["EID"].apply(parse_abstract)我使用的是熊猫的.apply()方法,而不是在一个循环中一个接一个地附加值,这是一个缓慢且容易出错的方法。
还要注意我是如何编写ab.description or ab.abstract的。https://pybliometrics.readthedocs.io/en/stable/classes/AbstractRetrieval.html指出,两者应该产生相同的结果,但可以是空的。使用此语句时,如果ab.description为空(即falsy),则将使用ab.abstract。
https://stackoverflow.com/questions/71278074
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号