
在Python中创建一个函数,用于根据多个条件从熊猫的dataframe值中创建桶
我问了这个问题,这对我有帮助,但现在我的任务更复杂了。
My有~100个列和值,有14个刻度。
{'Diseasetype': {0: 'Oncology',
1: 'Oncology',
2: 'Oncology',
3: 'Nononcology',
4: 'Nononcology',
5: 'Nononcology'},
'Procedures1': {0: 100, 1: 300, 2: 500, 3: 200, 4: 400, 5: 1000},
'Procedures2': {0: 1, 1: 3, 2: 5, 3: 2, 4: 4, 5: 10},
'Procedures100': {0: 1000, 1: 3000, 2: 5000, 3: 2000, 4: 4000, 5: 10000}}我希望将dataframe的每一列中的每个值转换为桶值。
我目前的解决办法是:
def encoding(col, labels):
return np.select([col<200, col.between(200,500), col.between(500,1000), col>1000], labels, 0)
onc_labels = [1,2,3,4]
nonc_labels = [11,22,33,44]
msk = df['Therapy_area'] == 'Oncology'
df[cols] = pd.concat((df.loc[msk, cols].apply(encoding, args=(onc_labels,)), df.loc[msk, cols].apply(encoding, args=(nonc_labels,)))).reset_index(drop=True)如果数据same的所有列都具有相同的比例,那么它可以很好地工作,但是它们不是。记住,我有14个不同的尺度。
我想更新上面的代码(或者获得另一种解决方案),这将允许我存储数据。I不能使用相同范围的值来存储所有内容.
我的逻辑如下:
如果Disease == Oncology和Procedures1具有此比例,则将值转换为这些桶(1、2、3)
如果Disease == Oncology和Procedures2具有此比例,则将值转换为这些桶(1、2、3)
如果Disease != Oncology和Procedures77具有此比例,则将值转换为这些桶(4、5、6)
比例和桶的例子:
肿瘤学Procedures1:< 200 = 1,200-400 = 2,>400 =3
肿瘤学Procedures2:<2= 1,2-4 = 2,>4 =3
肿瘤学Procedures3:< 2000 = 1,2000-4000 = 2,>4000 =3
Procedures1 for nonOncology:< 200 = 4,200-400 = 5,>400 =6
Procedures2 for nonOncology:<2= 4,2-4 = 5,>4 =6
Procedures3 for nonOncology:< 2000 = 4,2000-4000 = 5,>4000 =6
预期输出(乐意提供更多信息!)
Diseasetype Procedures1 Procedures2 Procedures100
Oncology 1 1 1
Oncology 2 2 2
Oncology 3 3 3
Nononcology 4 4 4
Nononcology 5 5 5
Nononcology 6 6 6回答 1
Stack Overflow用户
发布于 2022-02-25 14:14:46
我使用了一个带有所有比例的帮助文件(答案末尾的源):
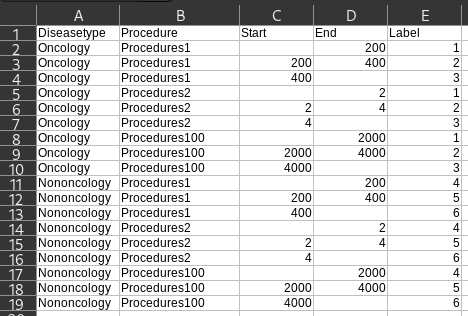
使用melt将您的数据拉平,然后使用query过滤出您的行,最后使用pivot重塑您的数据。您可以独立执行每一行以显示转换:
scales = pd.read_csv('scales.csv').fillna({'Start': -np.inf, 'End': np.inf})
out = (
df.melt('Diseasetype', var_name='Procedure', ignore_index=False).reset_index()
.merge(scales, on=['Diseasetype', 'Procedure'], how='left')
.query("value.between(Start, End)")
.pivot_table('Label', ['index', 'Diseasetype'], 'Procedure').astype(int)
.droplevel(0).rename_axis(columns=None).reset_index()
)输出:
>>> df
Diseasetype Procedures1 Procedures100 Procedures2
0 Oncology 1 1 1
1 Oncology 2 2 2
2 Oncology 3 3 3
3 Nononcology 4 4 4
4 Nononcology 5 5 5
5 Nononcology 6 6 6scales.csv含量
Diseasetype,Procedure,Start,End,Label
Oncology,Procedures1,,200,1
Oncology,Procedures1,200,400,2
Oncology,Procedures1,400,,3
Oncology,Procedures2,,2,1
Oncology,Procedures2,2,4,2
Oncology,Procedures2,4,,3
Oncology,Procedures100,,2000,1
Oncology,Procedures100,2000,4000,2
Oncology,Procedures100,4000,,3
Nononcology,Procedures1,,200,4
Nononcology,Procedures1,200,400,5
Nononcology,Procedures1,400,,6
Nononcology,Procedures2,,2,4
Nononcology,Procedures2,2,4,5
Nononcology,Procedures2,4,,6
Nononcology,Procedures100,,2000,4
Nononcology,Procedures100,2000,4000,5
Nononcology,Procedures100,4000,,6https://stackoverflow.com/questions/71266043
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号