
如何在不使用大熊猫的情况下对巨蟒中的csv进行分组
我有一个CSV文件与3行:“用户名”,“日期”,“能源节省”,我想总结一个特定用户的“节能日期”。
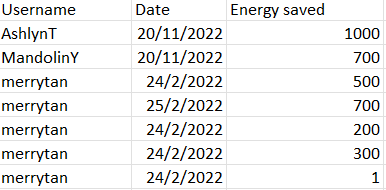
例如,如果是username = 'merrytan',我如何打印带有"merrytan“的所有行,以使节省的总能量按日期进行汇总?(日期: 24/2/2022总节能= 1001,日期: 24/2/2022总节能= 700)
我是蟒蛇的初学者,通常我会用熊猫来解决这个问题,但是这个项目是不允许的,所以我完全不知道该从哪里开始。我希望得到任何帮助和指导。谢谢。
回答 2
Stack Overflow用户
发布于 2022-02-24 04:12:23
打开csv文件的替代方法是使用本机python的csv模块。您将它们作为“文件”读取,只需提取所需的值即可。我使用第一列进行筛选,只保留相关列中相同的索引值。(这是指2.)
import csv
energy_saved = []
with open(r"D:\test_stack.csv", newline="") as csvfile:
file = csv.reader(csvfile)
for row in file:
if row[0]=="merrytan":
energy_saved.append(row[2])
energy_saved = sum(map(int, energy_saved)) 现在,您有了一个只是关心的值的列表,然后您可以对它们进行求和。
编辑-所以,我刚刚意识到,我遗漏了你的请求的时间部分完全lol。这是最新消息。
import csv
my_dict = {}
with open(r"D:\test_stack.csv", newline="") as file:
for row in csv.reader(file):
if row[0]=="merrytan":
my_dict[row[1]] = my_dict.get(row[1], 0) + int(row[2])因此,我们还需要获取文件的日期列。我们需要展示两个“行”,但是当Pandas被禁止时,我们将使用日期作为键和能量作为值去字典。
但是date列有重复的值(不管是有意的还是其他的),而字典要求键是唯一的。所以我们用一个循环。您将一个又一个日期值作为键,相应的能量作为值添加到新字典中,但是当它已经存在时,您将与现有值相加。
Stack Overflow用户
发布于 2022-02-24 03:53:56
我会将您的CSV文件转换为一个两级字典,其中包含用户名,然后将日期作为密钥。
infile = open("data.csv", "r").readlines()
savings = dict()
# Skip the first line of the CSV, since that has the column names
# not data
for row in infile[1:]:
username, date_col, saved = row.strip().split(",")
saved = int(saved)
if username in savings:
if date_col in savings[username]:
savings[username][date_col] = savings[username][date_col] + saved
else:
savings[username][date_col] = saved
else:
savings[username] = {date_col: saved}https://stackoverflow.com/questions/71246816
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号