
使用“父”CurrentMember筛选条件
使用“父”CurrentMember筛选条件
提问于 2022-02-24 02:03:23
以下是数据集:
CREATE TABLE Movies(id INT, name VARCHAR(50), genre VARCHAR(50), budget DECIMAL(10));
INSERT INTO Movies VALUES
(1, 'Pirates of the Caribbean', 'Fantasy', 379000000),
(2, 'Avengers', 'Superhero', 365000000),
(3, 'Star Wars', 'Science fiction', 275000000),
(4, 'John Carter', 'Science fiction', 264000000),
(5, 'Spider-Man', 'Superhero', 258000000),
(6, 'Harry Potter', 'Fantasy', 250000000),
(7, 'Avatar', 'Science fiction', 237000000);过滤相对于一个恒定值没有问题,例如获得预算超过3亿美元的所有电影:
WITH
MEMBER X AS SetToStr(Filter(Movie.[Name].[Name].Members - Movie.[Name].CurrentMember, Measures.Budget > 300000000))
SELECT
Movie.[Name].[Name].Members ON ROWS,
X ON COLUMNS
FROM
Cinema这意味着:
Avatar {[Movie].[Name].&[Avengers],[Movie].[Name].&[Pirates of the Caribbean]}
Avengers {[Movie].[Name].&[Pirates of the Caribbean]}
Harry Potter {[Movie].[Name].&[Avengers],[Movie].[Name].&[Pirates of the Caribbean]}
John Carter {[Movie].[Name].&[Avengers],[Movie].[Name].&[Pirates of the Caribbean]}
Pirates of the Caribbean {[Movie].[Name].&[Avengers]}
Spider-Man {[Movie].[Name].&[Avengers],[Movie].[Name].&[Pirates of the Caribbean]}
Star Wars {[Movie].[Name].&[Avengers],[Movie].[Name].&[Pirates of the Caribbean]}但是,如何比较当前电影的预算,而不是硬编码的3亿美元,让电影比现在更贵?
这将给{}的“加勒比海盗”,因为它是最昂贵的电影。
对于“复仇者”,它将是{ 'Pirates of the Caribbean' },因为这是第二最昂贵的,只有“加勒比海盗”更贵。
对于“阿凡达”,它会给所有其他电影,因为它是比较便宜的。
问题是,在Filter函数的条件下,CurrentMember指的是当前测试过的元组,而不是当前在ROWS轴上选择的元组。
回答 1
Stack Overflow用户
发布于 2022-02-24 06:00:07
我将首先根据预算值计算一组有序的电影,而不是对每部电影使用Filter()。然后可以使用SubSet和排名函数定义X。
下面是一个使用不同模式的示例,但我想您可以很容易地理解这个问题:
with
set ordered_continents as order( [Geography].[Geography].[Continent], -[Measures].[#Sales] )
member xx as SetToStr( SubSet( ordered_continents, 0, Rank( [Geography].[Geography].currentMember, ordered_continents) - 1))
select {[#Sales], [xx] } on 0, [Geography].[Geography].[Continent] on 1 from [Sales]
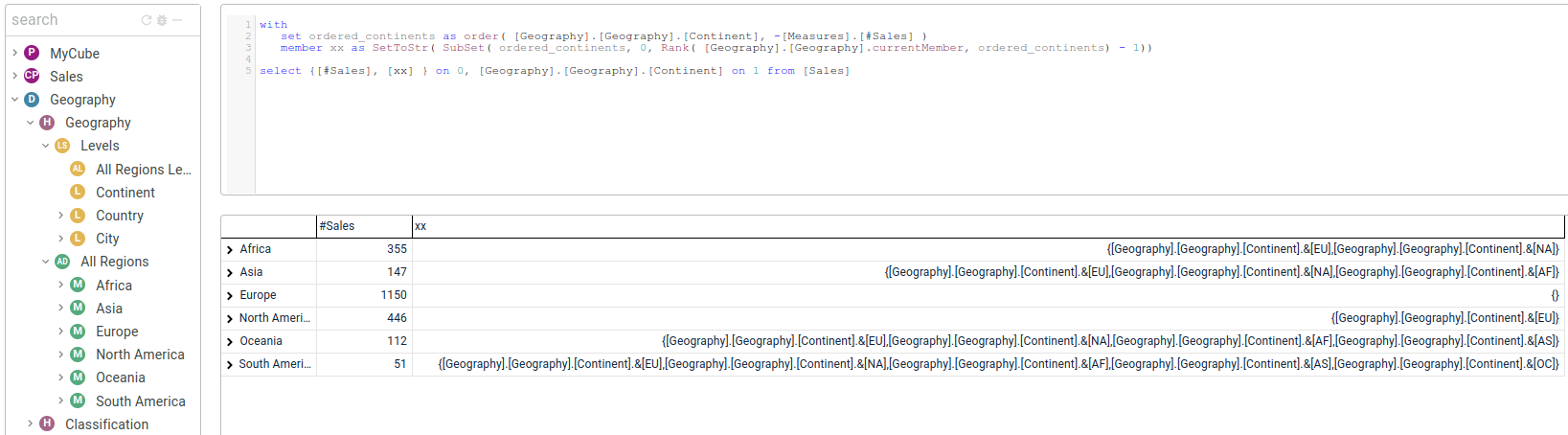
我不熟悉SSAS,所以我使用的是icCube,但我想MDX应该非常类似。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71246207
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号