
AWS Lambda:对于我的情况,我如何跳过python中的"For循环“中的第一个索引?
AWS Lambda:对于我的情况,我如何跳过python中的"For循环“中的第一个索引?
提问于 2022-02-19 12:28:40
我用lambda编写了一个python脚本,在其中我获取S3 CSV文件并将数据放入DynamoDb。一切都很顺利,但我想跳过循环的0索引,不知道如何在我的情况下执行该操作。以下是我的代码:
import json
import boto3
s3_client = boto3.client("s3")
dynamodb = boto3.resource("dynamodb")
student_table = dynamodb.Table('s3todynamodb')
def lambda_handler(event, context):
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
file_name = event['Records'][0]['s3']['object']['key']
file_object = s3_client.get_object(Bucket=source_bucket_name,Key=file_name)
print("file_object :",file_object)
file_content = file_object['Body'].read().decode("utf-8")
print("file_content :",file_content)
students = file_content.split("\n")
print("students :",students)
for student in students:
data = student.split(",")
print(data[0])
print(data[1])
print(data[2])
print(data[3])
print(data[4])
print(data[5])
print(data[6])
print(data[7])
print(data[8])
print(data[9])
print(data[10])
print(data[11])
print(data[12])
print(data[13])
print(data[14])
print(data[15])
print(data[16])
print(data[17])
print(data[18])
student_table.put_item(
Item = {
"Agent" : data[0],
"Agent answer rate" : data[1],
"Agent idle time" : data[2],
"Contacts missed" : data[3],
"Agent on contact time" : data[4],
"Nonproductive time" : data[5],
"Occupancy" : data[6],
"Online time" : data[7],
"Average after contact work time" : data[8],
"Average agent interaction time" : data[9],
"Average customer hold time" : data[10],
"Average handle time" : data[11],
"Contacts handled" : data[12],
"Contacts handled incoming" : data[13],
"Contacts handled outbound" : data[14],
"Contacts put on hold" : data[15],
"Contacts transferred out" : data[16],
"Contacts transferred out external" : data[17],
"Contacts transferred out internal" : data[18]
}
)在运行此代码时还有第二个问题,尽管它工作正常,但每次执行时,都会引发如下所述的错误:
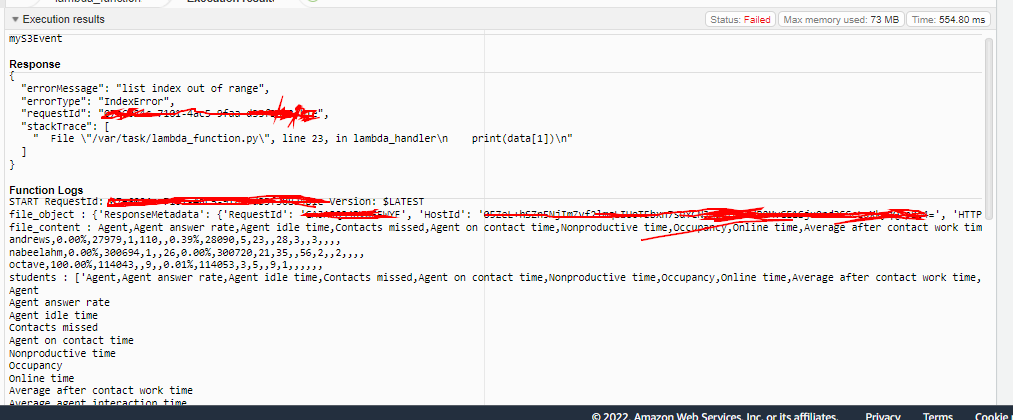
第一个问题=从1秒开始循环=索引列表超出范围误差。
如果有人提供任何帮助,我将非常感激。提前谢谢。
回答 3
Stack Overflow用户
发布于 2022-02-19 12:46:47
对于你能做的第一件事:
for student in students[1:]:第二个问题出现在第23行,这是
print(data[X])由于您的代码没有显示行,所以不太确定具体是哪一行。您必须打印出数据(没有索引)以确保检查。
Stack Overflow用户
发布于 2022-02-19 17:31:03
您几乎可以肯定地看到了一个空行,导致您的最后一个student.split(",")返回一个元素数组。
与手工解析CSV不同,使用内置Python模块为您解析CSV要容易得多:
from csv import DictReader
from io import StringIO
for Item in DictReader(StringIO(file_content)):
print(Item)Stack Overflow用户
发布于 2022-02-20 21:17:29
取代:
for student in students:使用
for index, student in enumerate(students):
if index == 0:
continue页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71184991
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号