
ggplot2中的分组百分比桶图
ggplot2中的分组百分比桶图
提问于 2022-02-18 18:52:02
我按以下方式运行代码:
ggplot(data, aes(fill=bolumtam, y=Languagevalue/tapply(Languagevalue, Language ,sum)[Language], x=Language)) +
geom_bar(aes( y=Languagevalue/tapply(Languagevalue, Language ,sum)[Language]), position="dodge", stat="identity")+
geom_text(aes( y=Languagevalue/tapply(Languagevalue, Language ,sum)[Language], label=scales::percent(Languagevalue/tapply(Languagevalue, Language ,sum)[Language]) ),
stat="identity", position=position_dodge(0.9), vjust=-0.5)+
scale_y_continuous(labels = scales::percent)生产:
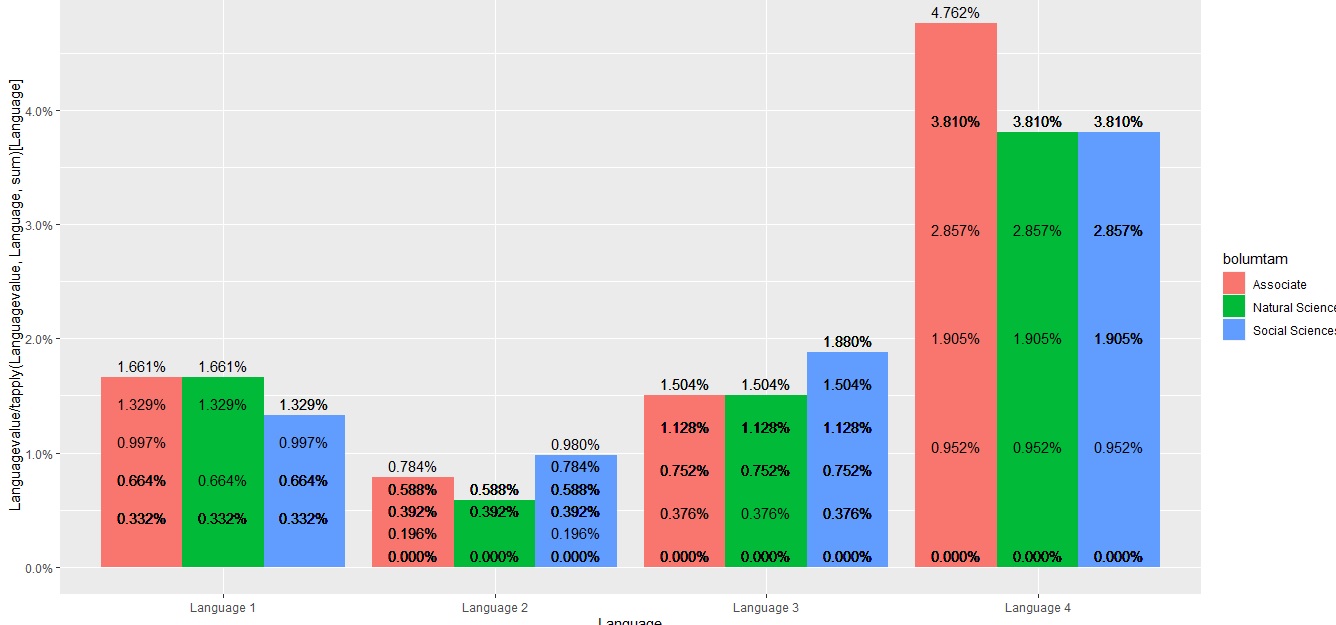
但是我想要生成一个图形,它的图案和百分比标签类似于这样:
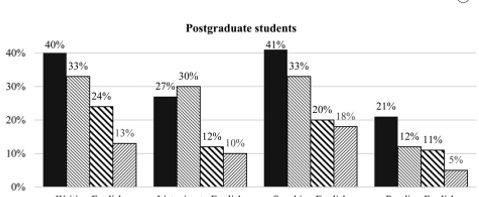
一些伪造的随机数据:
set.seed(100)
Language <- sample(c("Language 1", "Language 2", "Language 3", "Language 4"), 100, TRUE)
bolumtam <- sample(c("Associate", "Natural Sciences", "Social Sciences"), 100, TRUE)
Languagevalue <- sample(c(0, 1, 2, 3, 4, 5), 100, TRUE)
data <- data.frame(Language, bolumtam, Languagevalue)回答 1
Stack Overflow用户
发布于 2022-02-20 20:18:34
正如我在评论中提到的,在ggplot2中进行计数和百分比的所有计算,大多数时候都是最复杂和最容易出错的方法。相反,我建议在将数据传递给ggplot之前将其聚合起来。就我个人而言,我不建议使用模式,但是如果可以使用ggpattern包的话:
library(ggplot2)
library(ggpattern)
library(dplyr)
data1 <- data %>%
group_by(Language, bolumtam) %>%
summarise(Languagevalue = sum(Languagevalue), .groups = "drop") %>%
mutate(pct = Languagevalue / sum(Languagevalue))
ggplot(data1, aes(y = pct, x = Language)) +
geom_col_pattern(
aes(pattern = bolumtam, pattern_angle = bolumtam, pattern_spacing = bolumtam),
pattern_fill = 'black',
fill = 'white',
colour = 'black',
position = "dodge"
) +
geom_text(aes(label = scales::percent(pct), group = bolumtam), position = position_dodge(0.9), vjust = -0.5) +
scale_y_continuous(labels = scales::percent) +
scale_pattern_spacing_discrete(range = c(.01, .03))
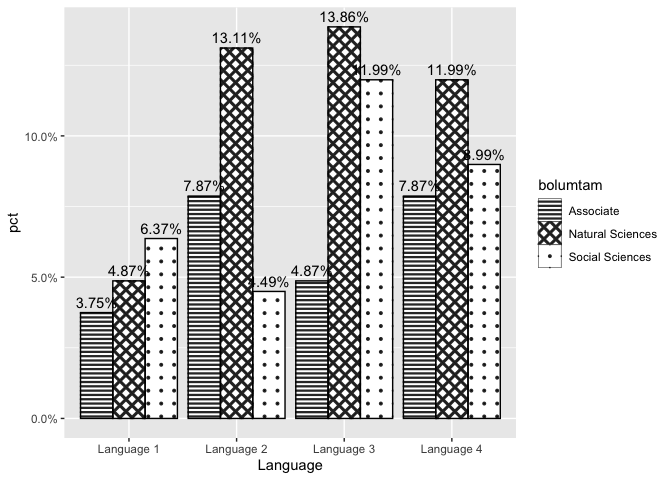
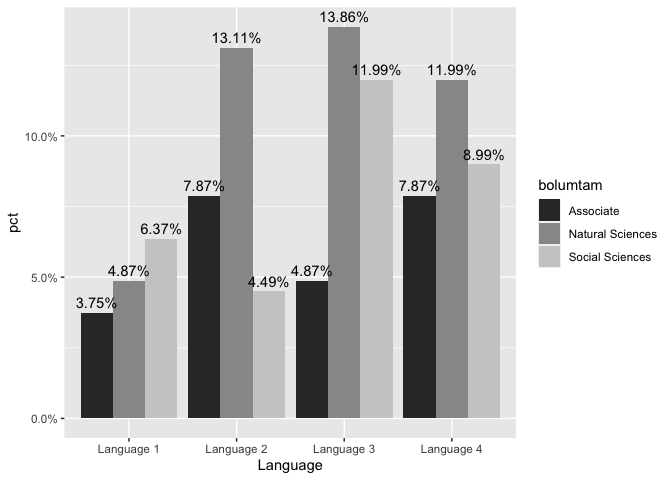
作为模式和颜色的替代,您可以使用灰色填充比例尺:
ggplot(data1, aes(y = pct, x = Language, fill = bolumtam)) +
geom_col(
position = "dodge"
) +
geom_text(aes(label = scales::percent(pct), group = bolumtam), position = position_dodge(0.9), vjust = -0.5) +
scale_y_continuous(labels = scales::percent) +
scale_fill_grey()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71178510
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号