
C++协同-什么时候,如何使用?
作为一个对协同技术概念非常陌生的新手C++程序员,我正在努力研究和利用这个特性。尽管在这里有关于coroutine的解释:What is a coroutine?
我还不确定何时以及如何使用协同线。提供了几个示例用例,但这些用例有其他解决方案,可以通过预C++20特性来实现:(例如:无限序列的延迟计算可以由具有私有内部状态变量的类完成)。
因此,我正在寻找协同作用特别有用的任何用法。
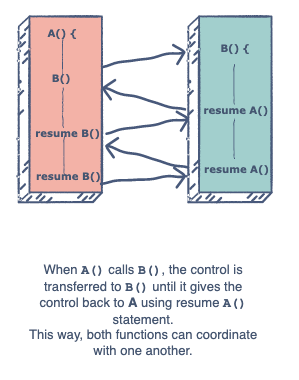
(来自Izana张贴的图片)
回答 4
Stack Overflow用户
发布于 2022-02-17 15:19:14
在这种情况下,"coroutine“一词有些过载。
称为“协同线”的一般编程概念是在您所指的问题中所描述的。C++20添加了一个名为"coroutines“的语言特性。虽然C++20的协同机制与编程概念有些相似,但它们并不完全相同。
在底层,这两个概念都建立在函数(或调用函数堆栈)停止执行并将执行控制权转移到其他人的能力之上。这是在期望控制最终会返回给暂时放弃执行的函数的情况下完成的。
C++协同与一般概念的不同之处在于它们的局限性和设计的应用。
co_await <expr>作为语言结构执行以下操作(用非常宽泛的笔画)。它询问表达式<expr>是否有当前要提供的结果值。如果它有一个结果,那么表达式将提取当前函数中的值并继续正常执行。
如果表达式目前无法解析(可能是因为<expr>在等待外部资源或异步进程或其他东西),则当前函数将暂停其执行并将控制返回给调用它的函数。协同线还附加到<expr>对象,这样,一旦<expr>有了值,它就应该用所述值恢复coroutine的执行。这种恢复可能发生在当前线程上,也可能不会发生。
所以我们看到了C++20协同线的模式。控件返回给调用方,但是coroutine的恢复取决于co_await编辑的值的性质。调用方获得一个对象,该对象表示coroutine将产生但尚未生成的未来值。呼叫者可以等待它的准备或去做其他的事情。它还可以自己对未来的值进行co_await,创建一个协作链,以便在计算值之后恢复。
我们也看到了一个主要的限制:暂停只适用于直接的功能。除非每个函数调用各自执行各自的co_await,否则不能挂起整个函数堆栈。
C++协同是3方之间的一种复杂舞蹈:等待中的表达式、等待的代码和协同线的调用者。使用co_yield本质上删除了这三个方中的一个。也就是说,预期不会涉及到已产生的表达式。它只是一个将被转储给调用者的值。因此,生成协同线只涉及协同线函数和调用方。产生C++协同线更接近概念上的“协同线”。
使用屈服协同线向调用方提供多个值通常称为“生成器”。这使代码变得多么“简单”取决于您的生成器框架(即: coroutine返回类型及其相关的协同机制)。但是,好的生成器框架可以向生成人员公开范围接口,允许您将C++20范围应用于它们,并执行各种有趣的组合。
Stack Overflow用户
发布于 2022-02-17 08:17:08
coroutine使异步编程更具可读性。
如果没有协同,我们将在异步编程中使用回调。
void callback(int data1, int data2)
{
// do something with data1, data2 after async op
// ...
}
void async_op(std::function<void()> callback)
{
// do some async operation
}
int main()
{
// do something
int data1;
int data2;
async_op(std::bind(callback, data1, data2));
return 0;
}如果有大量的回调,代码将很难阅读。如果我们使用coroutine,代码将是
#include <coroutine>
#include <functional>
struct promise;
struct coroutine : std::coroutine_handle<promise>
{
using promise_type = struct promise;
};
struct promise
{
coroutine get_return_object() { return {coroutine::from_promise(*this)}; }
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() {}
};
struct awaitable
{
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<promise> h)
{
func();
}
void await_resume() { }
std::function<void()> func;
};
void async_op()
{
// do some async operation
}
coroutine callasync()
{
// do somethine
int data1;
int data2;
co_await awaitable(async_op);
// do something with data1, data2 after async op
// ...
}
int main()
{
callasync();
return 0;
}Stack Overflow用户
发布于 2022-02-24 15:13:55
--在我看来,这些情况可以通过更简单的方法来实现:(例如:无限序列的延迟计算可以通过具有私有内部状态变量的类来完成)。
假设您正在编写一个应该与远程服务器交互的函数,创建TCP连接,登录一些多阶段的挑战/响应协议,进行查询并获得答复(通常是在TCP上的点滴和悬停),最终断开连接.如果您正在编写一个专门的函数来同步地这样做--就像您有一个专用线程那样--那么您的代码就可以非常自然地反映连接、请求和响应处理和断开的各个阶段,只需按照函数中语句的顺序和流控制的使用(for、while、switch、if)。在不同的点所需的数据将被定位在一个范围内,以反映它的使用,因此程序员更容易知道在每一点上什么是相关的。这是很容易写,维护和理解的。
但是,如果您希望与远程主机的交互是非阻塞的,并且在它们发生时在线程中执行其他工作,那么您可以使用一个具有私有内部状态变量的类来跟踪连接的状态,就像您建议的那样。但是,您的类不仅需要同步函数版本所需的相同变量(例如,用于组装传入消息的缓冲区),还需要变量来跟踪整个连接/处理步骤(例如,enum state { tcp_connection_pending, awaiting_challenge, awaiting_login_confirmation, awaiting_reply_to_message_x, awaiting_reply_to_message_y }、计数器、输出缓冲区)的位置,并且需要更复杂的代码才能跳回正确的处理步骤。您不再在特定的语句块中使用它来本地化数据,而是有一个由类数据成员组成的平面hodge,以及在理解代码的哪些部分是有效的或无效的时候需要额外的脑力开销等等。全是意大利面。(状态/策略设计模式可以帮助更好地构建这种结构,但有时使用运行时用于虚拟调度、动态分配等。)
协同例程提供了一种最好的双世界解决方案:您可以认为它们提供了一个额外的堆栈,用于调用看起来非常简洁、简单/快速的写入/维护/理解同步处理功能,但具有挂起和恢复而不是阻塞的能力,因此相同的线程可以推进连接处理以及其他工作(它甚至可以调用coroutine数千次来处理数千个远程连接,有效地在它们之间切换以保持工作在网络I/O发生时发生)。
让我们回到“无限序列的惰性计算”--从某种意义上说,协同可能会对此造成过度的影响,因为其中可能不存在多个处理阶段/状态或数据成员子集。尽管如此,一致性还是有一些好处的-如果提供合作管道的话。
https://stackoverflow.com/questions/71153205
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号