
从给定的csv中计算坏月份
我试着从数据中找出最糟糕的五个月,但我对这个过程并不确定,因为我很困惑。答案应该是类似的(2001年6月,2002年7月),但当我试图解决它时,我的答案并不像预期的那样。只对一月份的数据进行了排序。这就是我试图解决我的问题和csv数据文件的方式也提供在屏幕截图上。
我的解决办法如下:
PATH = "tourist_arrival.csv"
df = pd.read_csv(PATH)
print(df.sort_values(by=['Jan.','Feb.','Mar.','Apr.','May.','Jun.','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.'],ascending=False))
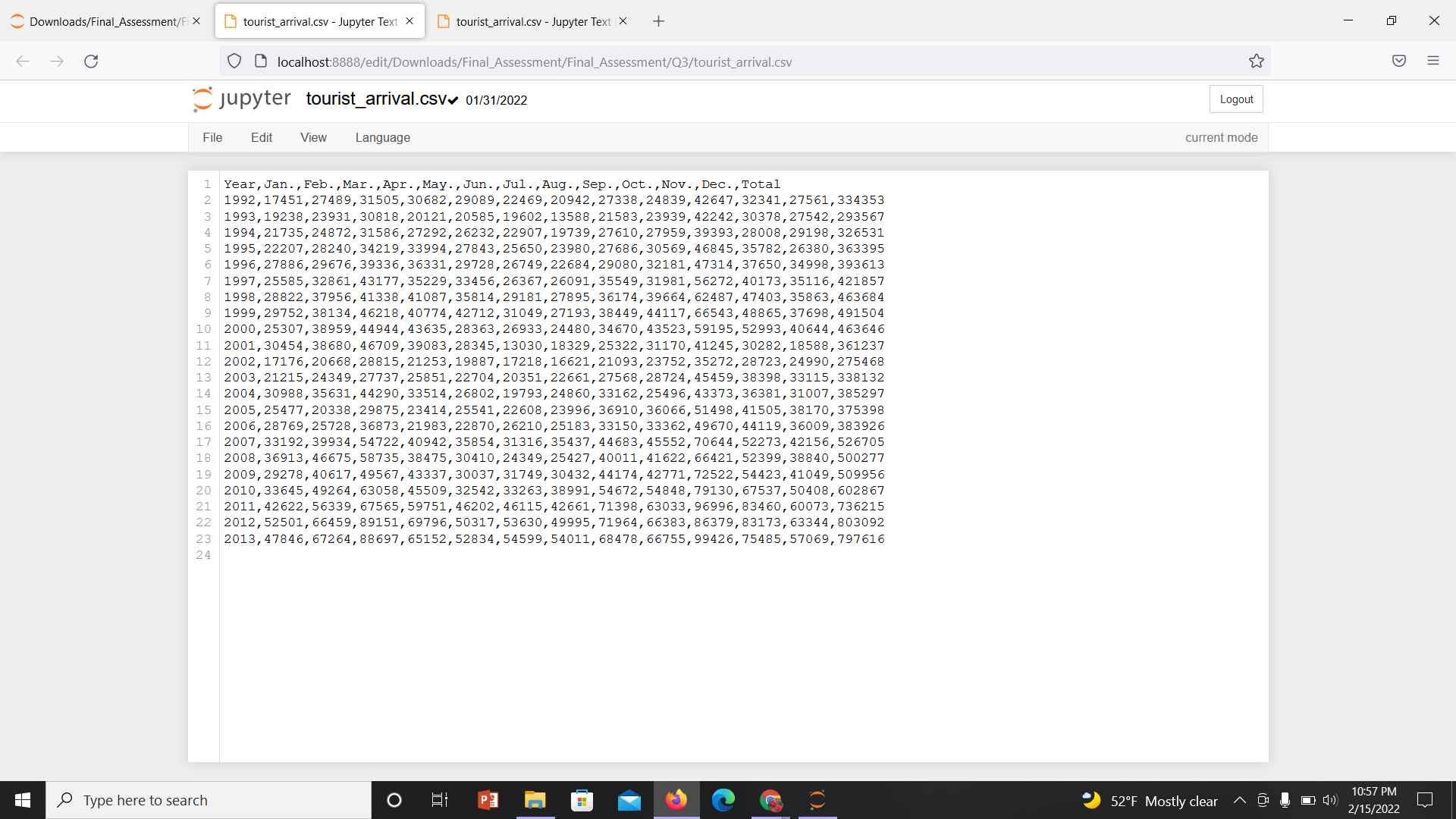
年、一月、二月、三月、四月、五月、六月、七月、八月、九月、十月、十二月、一九九二年十二月、一九九三年三月、四月、五月、六月、七月、九月、十一月、十二月、一九九二年十二月、一九九三年二月、一九九四年四月、五月、六月、七月、九月、十一月、十二月、一九九二年十二月、一九九三年四月、一九九四年五月、六月、七月、九月、十一月、十二月、一九九二年十二月、一九九三年四月、一九九四年五月、六月、七月、九月、十二月、一九九二年十二月、一九九四年十二月、一九九四年四月、五月、六月、七月、九月、十一月、十二月、一九九四年四月、五月、六月、七月、九月、十二月、一九九二年十二月、一九九四年十二月、一九九四年四月、五月、六月、七月、九月、十二月、一九九二年十二月、一九九四年十二月、一九九四年四月、五月、六月、七月、九月、
回答 1
Stack Overflow用户
发布于 2022-02-15 17:48:15
melt您的DataFrame,然后sort_values
output = df.melt("Year", df.drop(["Year", "Total"], axis=1).columns, var_name="Month").sort_values("value").reset_index(drop=True)
>>> output
Year Month value
0 2001 Jun. 13030
1 1993 Jul. 13588
2 2002 Jul. 16621
3 2002 Jan. 17176
4 2002 Jun. 17218
.. ... ... ...
259 2012 Oct. 86379
260 2013 Mar. 88697
261 2012 Mar. 89151
262 2011 Oct. 96996
263 2013 Oct. 99426
[264 rows x 3 columns]在最糟糕的5个月里,你可以做到:
>>> output.iloc[:5]
Year Month value
0 2001 Jun. 13030
1 1993 Jul. 13588
2 2002 Jul. 16621
3 2002 Jan. 17176
4 2002 Jun. 17218https://stackoverflow.com/questions/71130687
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号