
为什么stddev_over_time增加的范围向量越大
我正在为我们的web应用程序建立一个基于流量速度的异常检测。交通通常是接近的。在这个速率查询中可以看到每秒0.6次。我们有一个由被检查应用程序的几个实例组成的集群,因此我需要使用sum来确定下面的req/s或avg std偏差之和。
sum(rate(http_server_requests_seconds_count[1m]))
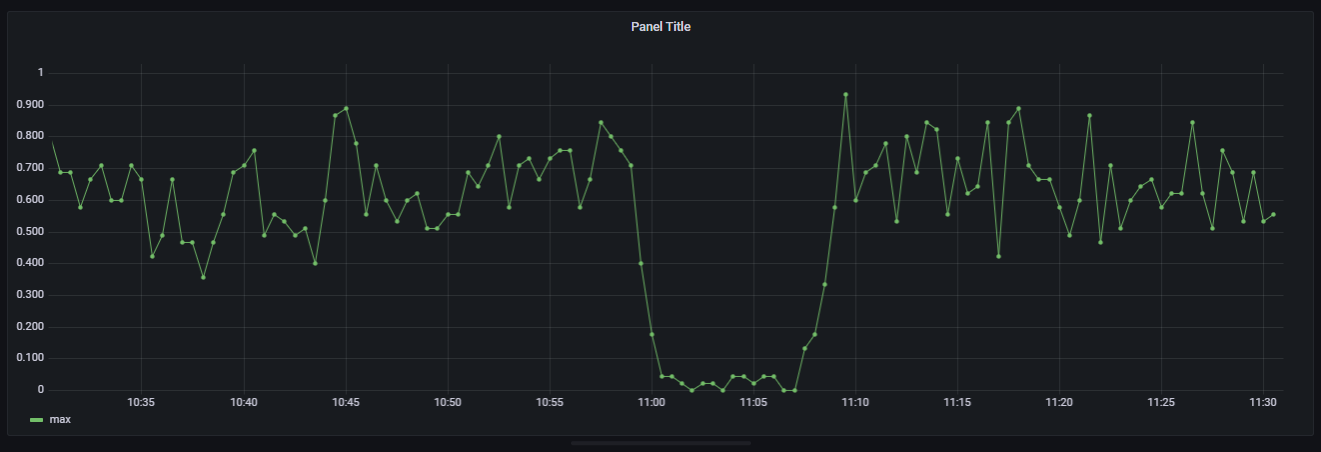
当我做一个间隔为1米的stddev_over_time时,它看起来是全面的。请注意,我需要过滤掉0,因为有时当某个特定的JVM在那个时刻没有接收到流量时,stddev_over_time无法计算出一个std偏差,然后我们得到0:
avg(stddev_over_time(http_server_requests_seconds_count[1m]) != 0)
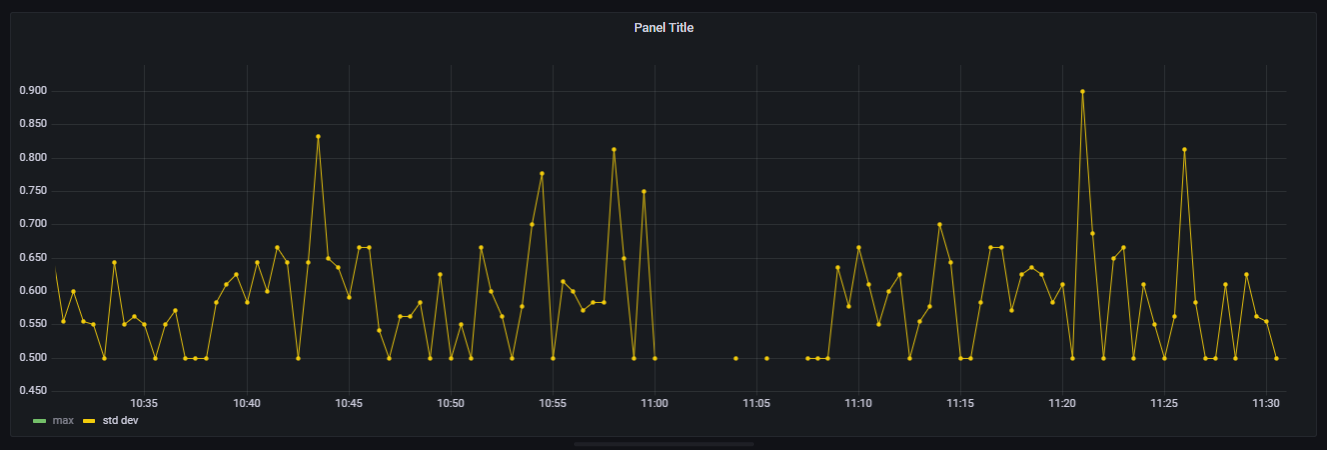
这很好,数值在0.5 (无偏差)到1-2 (相对不可能的偏差)的预期范围内。
我想要计算z分数,以检测流量异常,您可以在上午11点看到在我的第一个截图顶部(完全丢失流量->警报!)
Z-分数公式的定义如下:
z = (datapoint - mean_traffic) / "mean"_std_deviation因此,我想要这样的东西:
z = (sum(rate[1m]) - sum(rate[10m])) / avg(stddev_over_time[10m])但是它不起作用,因为当我将stddev_over_time的范围向量增加到10m时,值似乎是某种程度上的总结,不再能反映现实(std超过1)。如果我再加一次,比如30米,我的数值就会超过5。
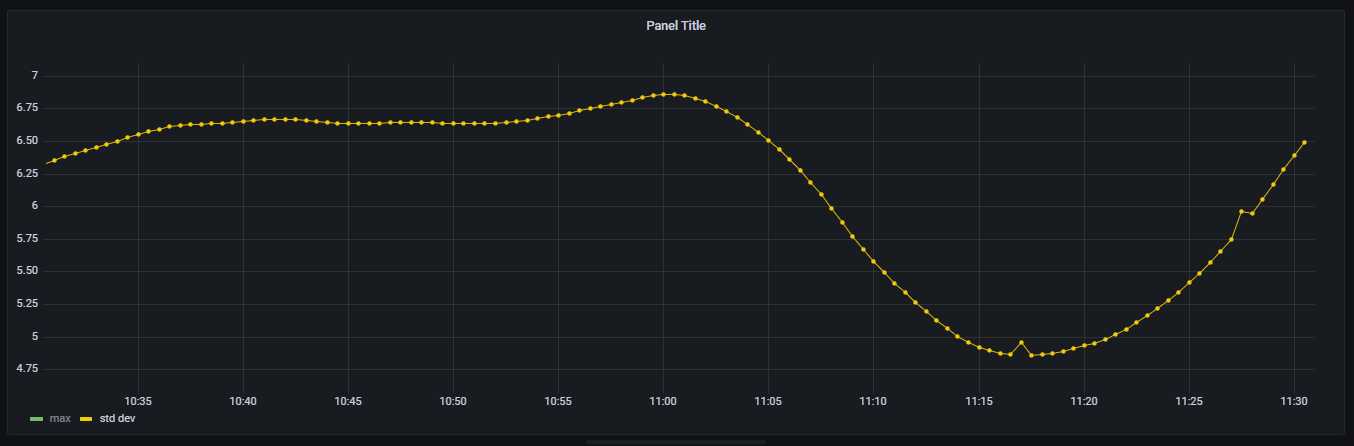
然而,我想要的是10米的性病偏差的移动平均值,因为我需要它来确定流量的当前率是否偏离平均std偏差(z-得分就是关于这个偏差的)。
回答 2
Stack Overflow用户
发布于 2022-08-14 11:40:11
以下是Z分计算的规范公式:
z(qi) = (qi - avg(q)) / stddev(q)在你的例子中,q = sum(rate(http_server_requests_seconds_count[1m]))。那么avg()和stddev()都必须在这个q上计算。
(
sum(rate(http_server_requests_seconds_count[1m]))
-
avg_over_time(sum(rate(http_server_requests_seconds_count[1m]))[10m:20s])
)
/
stddev_over_time(sum(rate(http_server_requests_seconds_count[1m]))[10m:20s])在查询中用更大的持续时间替换10m,以计算较大时间范围内的z-得分。
如您所见,这个查询包含同一个查询q的三个副本。这降低了查询的可读性,并可能使将来所有三个副本都需要同步更新时查询的维护变得复杂。有另一种类似普罗米修斯的监测解决方案,可以解决这些问题。该解决方案名为VictoriaMetrics + MetricsQL。它支持例如有模板,它允许多次引用相同的重复子查询。例如,可以将上面的查询简化为以下MetricsQL查询:
with (
q = sum(rate(http_server_requests_seconds_count[1m]))
)
(q - avg_over_time(q[10m:20s]))
/
stddev_over_time(q[10m:20s])P.p.s.我在VictoriaMetrics工作。
Stack Overflow用户
发布于 2022-08-11 16:31:21
z = (sum(rate(metric)[1m]) - sum(avg_over_time(metric[1w])) / sum(stddev_over_time(metric[1w]))试试这样的东西。参考文献:https://towardsdatascience.com/practical-monitoring-with-prometheus-grafana-part-iii-81f019ecee19
https://stackoverflow.com/questions/71079726
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号