
将ImportXML提取表提取到Google
将ImportXML提取表提取到Google
提问于 2022-02-07 15:31:51
我正在尝试从Google单张中提取出以下所有的Warcraftlog 表格。我只需要"names“和"count”和“百分比数字”。
=IMPORTXML("URL"; "XPATH")
=IMPORTXML("https://classic.warcraftlogs.com/reports/P4CQdFTp21wADfKX/#boss=-3&difficulty=0&type=auras&ability=31035"; "//table[contains(@id,'main-table-0')]")但是它不适用于Xpath中的//table[contains(@id,'main-table-0')]。使用//table/tr/td,它将提取warcraftlog网站上的几乎所有内容,除了我想要提取的表。
还有另一种使用XPath提取它们的方法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-02-08 03:40:32
- 您需要一个html表,所以切换到IMPORTHTML
- 从浏览器的“网络”选项卡中可以找到的另一个端点动态地从数据中提取数据,因此,可以对此提出请求。
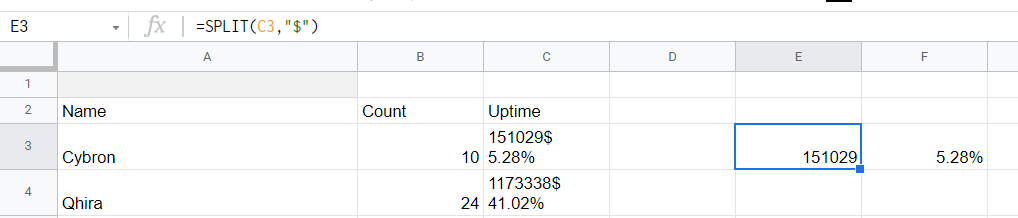
- 最后两个网页可见表列在检索到的表中是$分隔的,因此您需要拆分条目,例如使用工作表D列中的助手列(如果A1中的公式)包含拆分
=IMPORTHTML("https://classic.warcraftlogs.com/reports/auras/P4CQdFTp21wADfKX/0/0/6175385/buffs/31035/0/0/0/0/source/0/-3.0.0/0/Any/Any/0", "table",1)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71021144
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号