
Python中多列dataframe上的EDA for循环
Python中多列dataframe上的EDA for循环
提问于 2022-02-04 21:39:46
只是一个随机的q。如果有一个来自波士顿家庭ds的数据,df,我试图对其中的几个列进行EDA,设置为一个变量feature_cols,然后我可以用它来检查na,我们将如何处理呢?我有以下内容,它引发了一个错误:
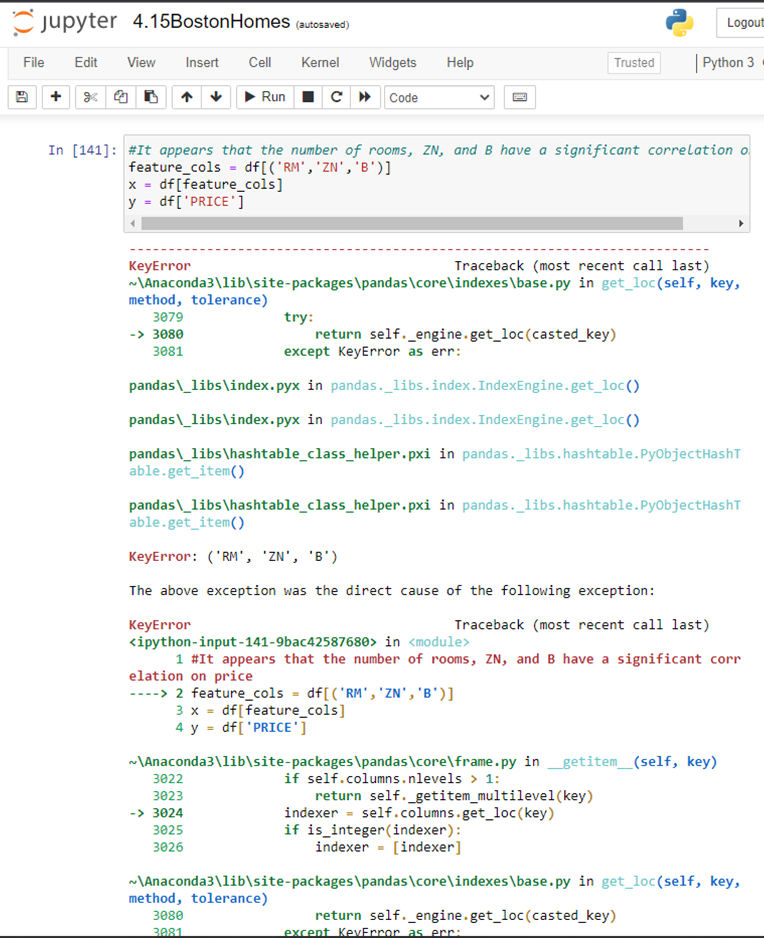
这就是我希望在做完上面这些之后要做的事情:
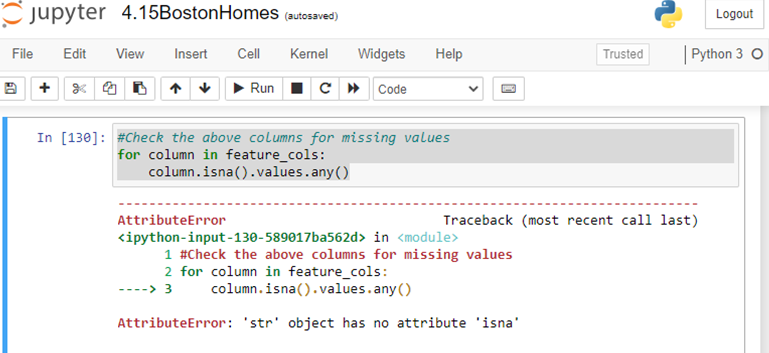
如有任何反馈,将不胜感激。提前谢谢。
回答 2
Stack Overflow用户
发布于 2022-02-04 21:42:55
您只需要将列的名称存储在数组中,以访问多个列,例如
feature_cols = ['RM','ZN','B']现在访问它作为
x = df[feature_cols]现在,要在df列上迭代,可以使用
for column in df[feature_cols]:
print(df[column]) # or anything根据您最新的评论,。如果您的最终目标是只查看空计数,则可以实现不循环。
df[feature_cols].info(verbose=True,null_count=True)Stack Overflow用户
发布于 2022-02-04 21:54:25
你的照片上有两个问题。首先是一个keyError,因为如果您想要访问dataframe的列子集,您需要传递列表中的列的名称,而不是元组,所以第一行应该是
feature_cols = df[['RM','ZN','B']]但是,这将返回一个包含三列的dataframe。您想要在for循环中使用的东西不能用于熊猫。我们通常迭代数据的行,而不是列,您可以使用一行:
df.isna().sum()这将打印dataframe的所有列名以及每列中缺失值的计数。当然,如果您只想检查列的子集,则可以。替换df buy df[list_of_columns_names]。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70993128
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号