
URL未知编码: Azure数据库中的mbcs
URL未知编码: Azure数据库中的mbcs
提问于 2022-02-04 04:16:26
我下载vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7。
下载来源:https://www.philadelphiafed.org/surveys-and-data/real-time-data-research/ads-点击“大多数当前广告索引葡萄酒”下载该文件。
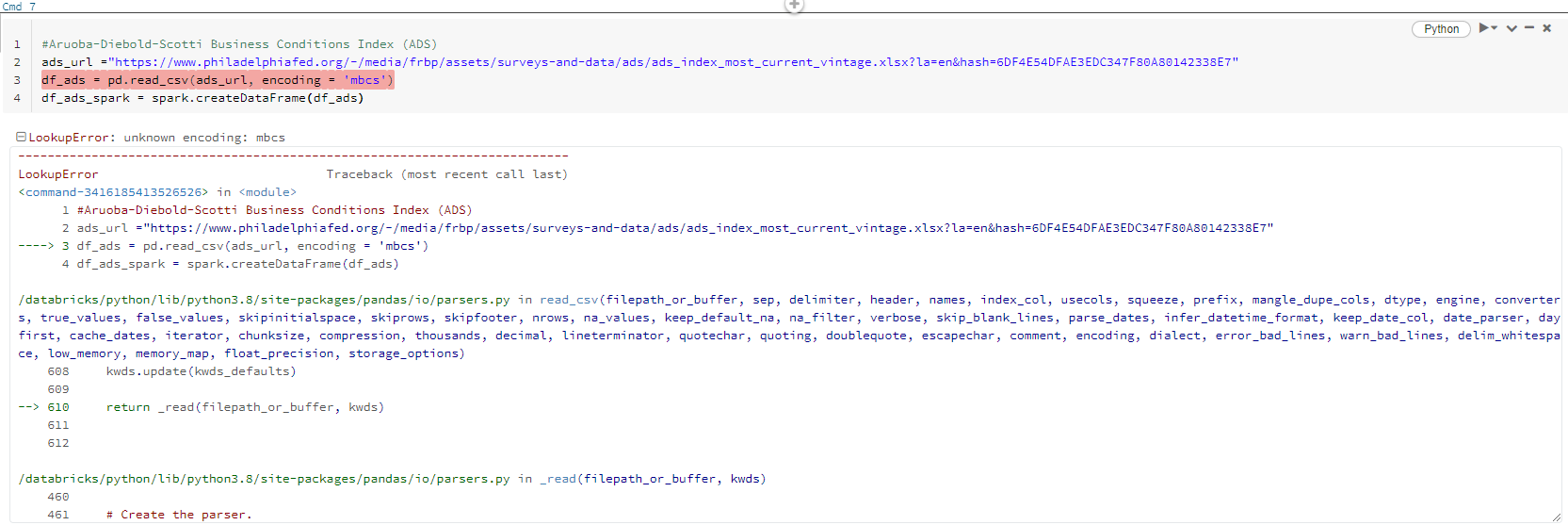
Notepad++显示下载文件是ANSI类型。

因此,我使用encoding = 'mbcs'对其进行解码。但是,存在一个错误unknown encoding: mbcs。
原始代码:
ads_url ="https://www.philadelphiafed.org/-/media/frbp/assets/surveys-and-data/ads/ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7"
df_ads = pd.read_csv(ads_url, encoding = 'mbcs')
df_ads_spark = spark.createDataFrame(df_ads)
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-02-04 20:50:59
在谷歌搜索之后,我发现这一项有效。如果您需要安装软件包,请安装它们。
import urllib.request
import chardet
from urllib.parse import unquote
import requests
ads_url = "https://www.philadelphiafed.org/-/media/frbp/assets/surveys-and-data/ads/ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7"
r = requests.get(ads_url)
open('ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7', 'wb').write(r.content)
df_ads = pd.read_excel('ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7')
df_ads_spark = spark.createDataFrame(df_ads)
display(df_ads_spark)Stack Overflow用户
发布于 2022-02-04 12:47:23
我不知道您是如何得出结论,您需要MBCS编码才能理解该文件,但我相信该文件是一个Excel文件。.xlsx扩展名表示它是一个zip文件(这解释了为什么它在Notepad++中不可读),其中包含表示电子表格的部分。你可以读取Databricks中的.xlsx文件。不需要提取压缩文件部分。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70981350
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号