
文本分析Python
文本分析Python
提问于 2022-02-02 15:58:59
我有一个带有文本的数据框架,我想提取啤酒的名称,这个名字总是在“饮酒.”这个短语之后。我不能只提取第三和第四个单词,因为有时会有一些额外的词,如在最后一行。我想把啤酒的全名提取成一根绳子。有人做过类似的事吗?
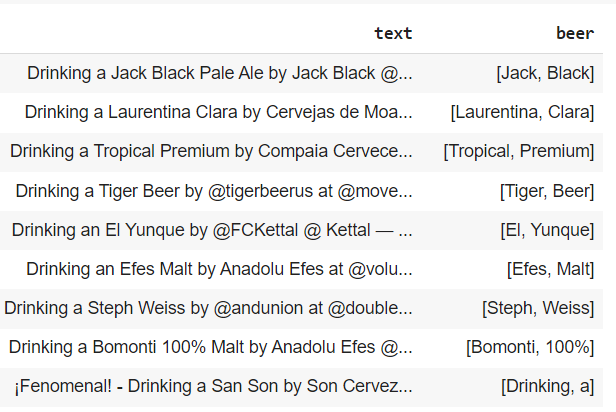
回答 3
Stack Overflow用户
发布于 2022-02-02 16:05:33
我建议将字符串转换为一个列表,找到索引I的“饮酒”,啤酒名称的索引是i+2和i+3。
text = text.lower().split()
i = text.index("drinking")
name = text[i+2] + " " + text[i+3]为
text = "Drinking a black pale ale"
name = "black pale"按照建议,您还可以找到"by“的索引j,然后从i+2循环到j-1。
Stack Overflow用户
发布于 2022-02-02 16:09:45
您可以在字符串上使用正则表达式来匹配“饮酒a”和"by“之间的所有内容。
(?<=drinking a)(.*)(?=by)这应该是可行的,你可以在一个在线的regex验证器上尝试它。有关此正则表达式工作的原因的参考:Regex Match all characters between two strings
Stack Overflow用户
发布于 2022-02-02 16:20:39
使用regexps
import re
lst = ['i am drinking a one beer', 'while my friend is drinking an other beer']
for item in lst:
match = re.search('drinking\s+an?\s+(\w+)\s+(\w+)', item, re.I)
if match:
print ('[{1}, {0}]'.format(match.group(1),match.group(2)))输出
[beer, one]
[beer, other]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70958785
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号