
GAM平滑交互作用差异-使用mgcv和value 0.6计算p值
我正在使用Gavin的有用的惠给包来提取因子变量的两个不同级别的两种平滑的差异。平滑是由精彩的mgcv软件包生成的。例如
library(mgcv)
library(gratia)
m1 <- gam(outcome ~ s(dep_var, by = fact_var) + fact_var, data = my.data)
diff1 <- difference_smooths(m1, smooth = "s(dep_var)")
draw(diff1)这给出了gam()调用中"by“变量的每个级别的两个平滑值之间的差异图。该图有一个95%的可信区间(CI)的差异。统计显着性,或0.05水平的统计显着性区域,是通过y=0线是否或在哪里跨越CI来评估的,其中y轴代表平滑之间的差异。
这里是Gavin站点中的一个例子,其中的"by“因子变量有3个级别。
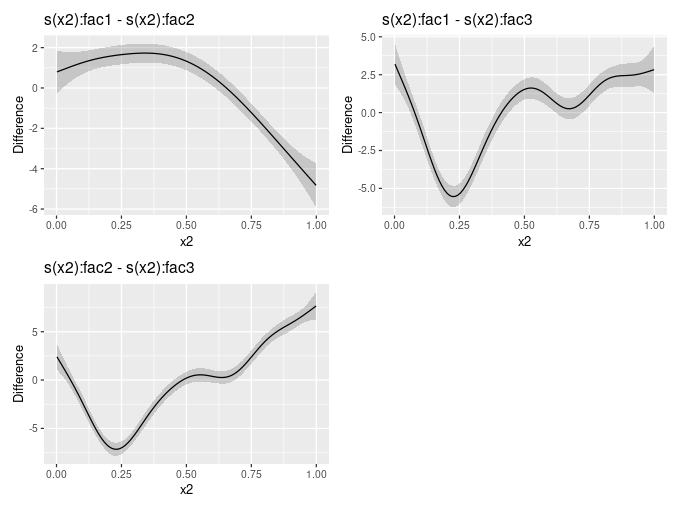
与几乎所有的图表相比,这些差异在统计学上是显著的( 0.05)。
这里是另一个示例,我使用带有2个级别的"by“变量生成。
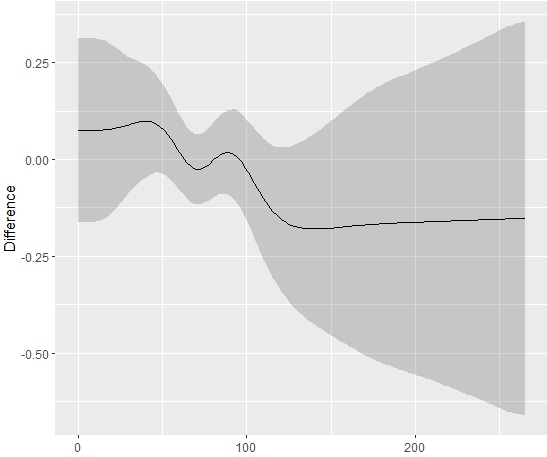
我的例子中的差异显然在任何地方都没有统计学意义。
在mgcv包中,根据卡方检验,输出一个平滑拟合的近似p值,检验系数均为0的零假设。
我的问题是,是否有人能建议一种计算p值的方法,以类似地评估这两种平滑之间的差异,而不是仅仅依靠图形证据?
difference_smooths()的输出是一个数据帧,平滑函数在光滑变量范围内的100个点处存在差异,差分的标准误差和CI的上、下界都有差异。
下面是用于解释difference_smooths()函数在这里输入链接描述的惠电0.4发布的链接
但惠悦现在的版本是0.6 在这里输入链接描述
提前感谢您抽出时间来考虑这个问题。
完成
回答 2
Stack Overflow用户
发布于 2022-02-02 06:32:10
获得by因子变量之间交互作用的p值的一种方法是通过激活difference_smooths()选项来操作ci_level函数。缺省值为0.95。可以对ci_level进行操作,以找到y=0不再存在于CI波段的级别。例如,当ci_level = my_level发生这种情况时,检验假设的p值是零,处处为零,则p值为1- my_level。
这并不完全令人满意。例如,这将需要一个小的手工实验,它可能很难准确地识别出零从CI下降。尽管可以编写一个函数来搜索随difference_smooths()输出的随ci_level变化的数据帧。这也不是完全令人满意的,因为非零CI的检测将取决于difference_smooths()选择的100个点来评估这两条曲线之间的差异。同样,对于使用mgcv的GAM来说,标准错误是近似的,所以这不会是太大的问题。
这是一个图,在这里,零第一次从CI下降。
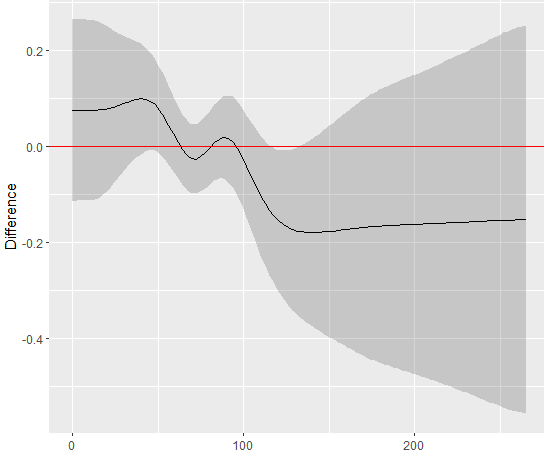
零在ci_level = 0.88辍学,还在ci_level = 0.89的休息时间。因此,p值为1-0.88= 0.12。
有人能想出更好的办法吗?
回复加文·辛普森2月19日的评论
非常感谢加文抽出时间发表意见。我不确定使用标准>= 0(对于负差异)是否是一个好方法。由于从后部提取,很可能会有许多不同的地方满足这一标准。我把你们的标准解释为样本的后验分布,计算出有多少差异符合这个标准,计算百分比,也就是p值。如果我误解了,请纠正我。使用这种方法,对于不同的gam模型,我始终得到在0.45-0.5之间的p值,即使在明确的情况下,平滑度的差异应该在统计上是显著的,至少在p= 0.05时,因为平滑周围的置信带在多个点上不包含零。
相反,我在想,也许比较每个差异的后继分布的方法会更好。例如
# get coefficients for the by smooths
coeff.level1 <- coef(gam.model1)[31:38]
coeff.level0 <- coef(gam.model1)[23:30]
# these indices are specific to my multi-variable gam.model1
# in my case 8 coefficients per smooth
# get posterior coefficients variances for the by smooths' coefficients
vp_level1 <- gam.model1$Vp[31:38, 31:38]
vp_level0 <- gam.model1$Vp[23:30, 23:30]
#run the simulation to get the distribution of each
#difference coefficient using the joint variance
library(MASS)
no.draws = 1000
sim <- mvrnorm(n = no.draws, (coeff.level1 - coeff.level0),
(vp_level1 + vp_level0))
# sim is a no.draws X no. of coefficients (8 in my case) matrix
# put the results into a data.frame.
y.group <- data.frame(y = as.vector(sim),
group = c(rep(1,no.draws), rep(2,no.draws),
rep(3,no.draws), rep(4,no.draws),
rep(5,no.draws), rep(6,no.draws),
rep(7,no.draws), rep(8,no.draws)) )
# y has the differences sampled from their posterior distributions.
# group is just a grouping name for the 8 sets of differences,
# (one set for each difference in coefficients)
# compare means with a linear regression
lm.test <- lm(y ~ as.factor(group), data = y.group)
summary(lm.test)
# The p value for the F statistic tells you how
# compatible the data are with the null hypothesis that
# all the group means are equal to each other.
# Same F statistic and p value from
anova(lm.test)有人可能会说,如果所有系数都不是相等的,那么它们都不可能等于零,但这不是我们想要的。summary(mgcv::gam.model1)给出的平滑拟合试验的基础
是所有系数== 0的联合测试。这将来自于一种似然比检验,其中模型是否适合某一项进行了比较。
我希望有一些想法,如何做到这两个平滑之间的区别。
现在我已经走到了这一步,我重新考虑了您最初提出的使用标准>= 0(用于负差异)的建议。我将此重新解释为每个模拟系数差分布(在我的例子中为8)的意义,当这种情况发生时计数,并创建一个表,其中每一行(我的情况,8)都是其中一个分布,其中有两个列包含这个计数和(模拟数减去计数),然后在这个表上运行一个卡方检验。当我这样做的时候,我得到了一个非常低的p值,当我认为我不应该这样做的时候,在几乎所有曝光水平之间的平滑差CI中,0是很好的。也许我还是误解了你的建议。
跟踪思想2月24日
在后续的思考中,我们可以创建一个变量来表示by因子和连续变量之间的相互作用。
library(dplyr)
my.dat <- my.dat %>% mutate(interact.var =
ifelse(factor.2levels == "yes", 1, 0)*cont.var)这里我假设因子2层有级别( "no“,"yes"),”no“是引用级别。ifelse函数创建一个虚拟变量,该变量与连续变量相乘以生成交互式变量。
然后,我们将这个交互变量放置在GAM中,得到通常的拟合统计检验,即检验所有系数== 0。
Stack Overflow用户
发布于 2022-03-04 07:12:10
@GavinSimpson实际上在2017年发布了一种如何获得两种平滑之间的差异并评估其统计意义的方法( 这里 )。感谢Matteo Fasiolo为我指明了那个方向。
在这种方法中,by变量被转换为有序的范畴变量,这使得mgcv::gam与参考级别相比产生了差异平滑。然后用gam模型的summary命令以通常的方式检验差异平滑的统计意义。
然而,如果我有误解的话,纠正我的错误,有序因子法使平滑为主要影响现在是平滑的参考水平的有序因素。
我建议的方法,见标题下的主帖子,后续思想2月24日,其中创建了交互变量,对于差异平滑的p值给出了一个几乎相同的结果,但对于主要效果并没有改变光滑。它也不改变被分类变量的截距和线性项,这两者也都随着有序变量的方法而改变。
https://stackoverflow.com/questions/70922283
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号